




I. Il y a un package pour tout▲
Au début, vous pourriez être tenté de définir des solutions personnelles aux problèmes qui ne semblent pas avoir de solution en utilisant le package de base du langage R. C'est une mauvaise approche pour plusieurs raisons, la principale étant qu'il y a probablement un package que vous pourriez utiliser pour vous simplifier la tâche et vous assurer que votre solution est correcte. Vous devez connaître — et utiliser — vos packages R, dont la plupart sont stockés dans le CRAN (Comprehensive R Network).
Le listing 1 vous montre un exemple de package qui vous facilite la vie.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
library(sandwich)
library(lmtest)
xs <- rnorm(1000,10,2)
ys <- xs*2
X <- cbind(1,xs)
plot(ys~xs)
ys <- ys + xs * rnorm(1000,1,1)
plot(ys~xs)
mod <- lm(ys~xs)
summary(mod)
ehat <- diag(residuals(mod)^2)
sqrt(diag(solve(t(X)%*%X) %*% t(X) %*% ehat %*% X %*% solve(t(X)%*%X)))
coeftest(mod, vcov = sandwich)
Le code du listing 1 crée deux vecteurs de données à utiliser dans une régression (lignes 3-5). Les données sont créées de sorte que X et Y soient liés, mais il y a l’hétéroscédasticité. Le code de la ligne 7 montre comment l'hétéroscédasticité est créée. Les Y, qui sont déjà liés aux X, ont un composant aléatoire qui est créé avec les X. L'hétéroscédasticité n'entrave pas votre capacité à estimer une régression. Cependant, les erreurs-types des coefficients ne sont pas fiables, donc la régression est estimée mais pas vraiment évaluée. Ensuite, la régression est exécutée, et nous pouvons visualiser les erreurs standard (les erreurs standard incorrectes) qui proviennent de la fonction summary.
Pour calculer les erreurs, il faut créer la matrice résiduelle, ainsi qu'une matrice X (lignes 11 et 5). La formule matricielle sera appliquée à ces matrices pour obtenir des erreurs-types robustes (ligne 12). Regardez ces lignes pour vous rappeler comment le faire et vous devez inévitablement faire des essais pour détecter les erreurs. La ligne suivante, ligne 13, montre comment obtenir les erreurs standard robustes en utilisant les packages sandwich et lmtest.
Ces packages sont chargés aux lignes 1 et 2. Pour les utiliser, ils doivent être installés en utilisant la fonction install.packages (). Les packages sont plus faciles à utiliser et sont moins susceptibles de créer une erreur que si vous essayez une approche maison. Les packages exécutent non seulement les tâches que le package de base R ne peut pas effectuer, mais ils ont également été contrôlés par la communauté open source.
Les packages en R ont une excellente documentation standardisée, et il y a des exemples d’utilisation qui peuvent vous être utiles. Vous devriez inclure des packages dans le package de base du langage R pour résoudre vos problèmes, en vous assurant de comprendre et d'utiliser ces packages de façon adéquate. Ainsi votre code R peut être correct.
II. Comment gérer vos données▲
Il est important de comprendre la structuration des données dans R. Les scripts et les résultats de cette section décrivent certaines des structures de données disponibles, notamment les vecteurs, les matrices, les données et les listes.
II-A. Cas d'utilisation des structures de données▲
Jetons un coup d'œil aux cas d'utilisation pour chaque type de structure de données.
- Vecteurs : vous utiliserez ce type de données lorsque vous devez stocker de simples variables du même type, telles que les poids de tous les Ford F-150 dans un ensemble de données.
- Matrices : à utiliser lorsque vous devez stocker plusieurs variables du même type ou lorsque vous devez déplacer ou convertir des données dans R. De nombreuses fonctions R nécessitent l'entrée de données dans une matrice, telles que l'analyse des composants principaux.
- Tableaux de données : ils permettent de stocker plusieurs variables de différents types. Ils sont parfaits pour les ensembles de données d'observation.
- Listes : Utilisez cette option pour déplacer des données lorsque vous n'êtes pas sûr de la longueur du type de données. Les listes sont le type de retour idéal pour des résultats des fonctions.
Commençons par examiner les vecteurs, comme le montre le Listing 2. Les vecteurs sont une collection de données de même type. Ils sont l'unité de base pour déplacer des données dans R, et ils sont créés avec la fonction C. Ils sont faciles à créer, et les éléments individuels peuvent être visualisés en utilisant un index (qui commence à 1, et non à 0).
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
#Vectors
vex <- c(1,5,3)
vex
[1] 1 5 3
vex <- c(1 + 2i,4,5)
vex
[1] 1+2i 4+0i 5+0i
vex <- c(TRUE,1,0,1)
vex
[1] 1 1 0 1
vex <- c("This","That",1)
vex
[1] "This" "That" "1"
vex[1]
[1] "This"
Le code montre que lorsque vous alimentez la fonction C, les anciennes données disparaissent. Les nouvelles données prennent simplement leur place.
C'est également le cas des matrices, comme le montre le listing 3. Les matrices sont une série de deux ou plusieurs vecteurs dimensionnels. R possède également des tableaux multidimensionnels, qui sont des matrices de dimension supérieure. Vous pouvez prendre deux vecteurs et créer une matrice. Si vous ne spécifiez aucune autre option, la matrice résultante, mat1, est juste une matrice à une colonne. En spécifiant le nombre de lignes que vous voulez dans mat1 (par exemple 2), la matrice résultante sera une matrice 2x5.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
#Matrices
v1 <- c(0:4)
v2 <- c(5:10)
mat1 <- matrix(c(v1,v2))
mat1
[,1]
[1,] 0
[2,] 1
[3,] 2
[4,] 3
[5,] 4
[6,] 5
[7,] 6
[8,] 7
[9,] 8
[10,] 9
mat1 <- matrix(c(v1,v2),nrow=2)
mat1
[,1] [,2] [,3] [,4] [,5]
[1,] 0 2 4 6 8
[2,] 1 3 5 7 9
mat2 <- matrix(c(v1,v2),ncol=2)
mat1*mat2
Error in mat1 * mat2 : non-conformable arrays
mat3 <- mat1%*%mat2
mat3[1,2]
[1] 160
Vous remarquerez que les vecteurs n'ont pas été empilés les uns sur les autres pour créer la matrice. Car la matrice entre les données par colonne, sauf indication contraire. Ensuite, si vous créez la même matrice mais spécifiez deux colonnes, vous ne pouvez plus multiplier les matrices. Les matrices prennent par défaut une multiplication et une division cellule par cellule, et non une multiplication matricielle. Vous pouvez spécifier la multiplication matricielle en utilisant %*. Dans ces conditions, les matrices se multiplient afin que vous puissiez accéder à la cellule dans la première ligne et la deuxième colonne de la matrice résultante.
À présent, étudions les tableaux de données à travers le listing 4.
Le code suivant crée un tableau de données en utilisant la fonction data.frame. Vous pouvez ajouter des données sans spécifier les noms de variables. Dans cet exemple, les variables ont été nommées. Vous remarquerez que les tableaux de données stockent des données de différents types alors que les matrices et les vecteurs ne stockent qu’un seul type de données.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
#Dataframes
df <- data.frame(Bool = sample(c(TRUE,FALSE),100,replace=T),Int =
c(1:100),String=sample(LETTERS,100,replace=TRUE))
df$Bool
[1] FALSE TRUE TRUE FALSE TRUE TRUE FALSE FALSE FALSE TRUE TRUE
FALSE TRUE TRUE FALSE TRUE FALSE TRUE TRUE TRUE FALSE TRUE
[23] FALSE TRUE FALSE FALSE FALSE TRUE FALSE TRUE FALSE TRUE FALSE
TRUE TRUE TRUE TRUE FALSE TRUE TRUE TRUE FALSE TRUE TRUE
[45] FALSE FALSE FALSE FALSE TRUE FALSE FALSE TRUE FALSE TRUE TRUE
FALSE TRUE TRUE FALSE TRUE TRUE FALSE FALSE FALSE TRUE FALSE
[67] TRUE FALSE FALSE FALSE FALSE FALSE TRUE FALSE TRUE TRUE TRUE
FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE TRUE
[89] TRUE FALSE TRUE TRUE FALSE FALSE FALSE FALSE FALSE FALSE TRUE
TRUE
df[df$Bool,]
Bool Int String
2 TRUE 2 Z
3 TRUE 3 R
5 TRUE 5 K
6 TRUE 6 T
10 TRUE 10 O
11 TRUE 11 U
13 TRUE 13 Y
14 TRUE 14 Z
16 TRUE 16 N
df[df$Bool,3]
[1] Z R K T O U Y Z N H D L B H N L D Z R M I W W I M D A C B R S M Y Y F V B
W P Q Q S M Y K Z J V I
Levels: A B C D E F H I J K L M N O P Q R S T U V W X Y Z
df$String[df$Bool]
[1] Z R K T O U Y Z N H D L B H N L D Z R M I W W I M D A C B R S M Y Y F V B
W P Q Q S M Y K Z J V I
Levels: A B C D E F H I J K L M N O P Q R S T U V W X Y Z
df$NewVar <- c(1:101)
Error in `$<-.data.frame`(`*tmp*`, "NewVar", value = 1:101) :
replacement has 101 rows, data has 100
df$NewVar <- c(1:99)
Error in `$<-.data.frame`(`*tmp*`, "NewVar", value = 1:99) :
replacement has 99 rows, data has 100
Dans le code, vous pouvez voir la sortie lorsque la variable de base de données, Bool, est appelée avec l'opérateur $ (ligne 4).
C'est un moyen simple et courant pour accéder à vos données lorsqu'elles sont stockées dans un tableau de données. Ensuite, vous pouvez accéder à des lignes ou colonnes spécifiques à l'aide de Bool ou de 1 et de 0. df[df$ Bool,] (ligne 5) imprime toutes les lignes dans lesquelles Bool est TRUE. Dans cette liste, puisqu’aucune colonne n'est spécifiée, elle imprime toutes les colonnes.
L'appel suivant spécifie la troisième colonne, de sorte que seules les valeurs de la variable String soient imprimées (ligne 6). Il y a d’autres façons de le faire que vous verrez plus tard. L'opérateur $ est utilisé pour spécifier la variable String, ce qui peut être considéré comme un vecteur, puis les valeurs Bool sont utilisées pour spécifier les valeurs de sortie. Parce que la variable String a été spécifiée en premier, il n'est pas nécessaire de spécifier des colonnes lors de l'utilisation de Bool pour choisir ce qu'il faut imprimer (ligne 7). Il est évident que les tableaux de données sont beaucoup plus flexibles que les vecteurs et les matrices. Cependant, les deux dernières lignes du script ci-dessus montrent que toutes les nouvelles variables doivent avoir la même longueur. Ce n'est pas énormément restrictif, mais les listes, dont nous allons maintenant parler, sont moins restrictives lorsqu'il s'agit d'ajouter des données.
Le Listing 5 montre le code utilisé pour créer une liste avec trois vecteurs de longueurs différentes. Vous pouvez toujours utiliser l'opérateur $ pour accéder aux objets de la liste, ou le [[]]. Une autre chose importante à propos des listes est leur capacité à contenir d'autres objets de données. Pour qu'une liste contienne d'autres objets de données, vous pouvez ajouter un tableau de données à la liste (ligne 6). Le tableau de données est stocké et peut toujours être consulté (ligne 8). En outre, vous n’êtes pas obligé de spécifier le nom de la liste. Tout cela vous servira lors de la création de fonctions ou de packages. Par habitude, certains créeront beaucoup de types de données différents qui doivent être stockés de différentes manières. Les listes deviennent utiles parce que tous ces différents types d'objets de données peuvent être regroupés et retournés ensemble.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
#Lists
ls <- list(Bool = sample(c(TRUE,FALSE),50,replace=T),Int =
c(1:75),String=sample(LETTERS,100,replace=TRUE))
ls$String
[1] "O" "F" "E" "U" "O" "P" "E" "V" "G" "Z" "T" "F" "T" "C" "J" "P" "G"
"L" "M" "E" "O" "T" "E" "R" "A" "Z" "E" "Y" "N" "Y" "U" "N" "E"
[34] "T" "N" "W" "Z" "D" "S" "R" "P" "C" "H" "G" "N" "Y" "P" "M" "H" "A"
"J" "Y" "C" "C" "Y" "S" "P" "J" "W" "J" "H" "E" "B" "Z" "X" "T"
[67] "B" "M" "I" "P" "V" "I" "H" "M" "D" "I" "T" "L" "J" "F" "M" "B" "J"
"E" "G" "K" "E" "U" "F" "U" "T" "L" "B" "Z" "U" "X" "U" "P" "D"
[100] "W"
Ls[[3]]
[1] "O" "F" "E" "U" "O" "P" "E" "V" "G" "Z" "T" "F" "T" "C" "J" "P" "G"
"L" "M" "E" "O" "T" "E" "R" "A" "Z" "E" "Y" "N" "Y" "U" "N" "E"
[34] "T" "N" "W" "Z" "D" "S" "R" "P" "C" "H" "G" "N" "Y" "P" "M" "H" "A"
"J" "Y" "C" "C" "Y" "S" "P" "J" "W" "J" "H" "E" "B" "Z" "X" "T"
[67] "B" "M" "I" "P" "V" "I" "H" "M" "D" "I" "T" "L" "J" "F" "M" "B" "J"
"E" "G" "K" "E" "U" "F" "U" "T" "L" "B" "Z" "U" "X" "U" "P" "D"
[100] "W"
ls[[4]] <- df
Ls[[4]]
Bool Int String
1 FALSE 1 Q
2 TRUE 2 Z
3 TRUE 3 R
4 FALSE 4 M
5 TRUE 5 K
6 TRUE 6 T
Ls[[4]][2:5,1]
[1] TRUE TRUE FALSE TRUE
names(ls)
[1] "Bool" "Int" "String" ""
Il y a beaucoup à apprendre sur les données dans R, mais comprendre comment utiliser des vecteurs, des matrices, des tableaux de données et des listes vous aidera pour un début.
III. Dans le monde des EDI, RStudio est roi ▲
Rstudio est le seul EDI que vous devez utiliser lorsque vous écrivez des scripts R. Il regroupe tout ce dont vous avez besoin en un seul outil et est indispensable dans l'utilisation intégrée de Sweave et R Markdown. Ces outils permettent la création de documents contenant du code, des résultats, des graphiques et du texte. La création de ces documents est scénarisée et est donc entièrement reproductible. Un autre avantage de RStudio est le débogueur R, qui est intégré dans l'EDI. Le Listing 6 nous montre un exemple avec le débogueur.
2.
3.
4.
5.
6.
7.
8.
9.
testF <- function(x,y){
if(length(x) == length(y)){testF1(x,y)}
}
testF1 <- function(x,y){
print(cbind(x,y))
}
x <- c(1:10)
y <- c(11:21)
testF(x,y)
Si vous pensez que x et y seront affichés, vous serez déçu que ce ne soit pas le cas. En supposant que vous ne pouvez pas comprendre pourquoi vous-même, entrez les commandes suivantes dans la console pour démarrer le débogueur (voir la figure 1).
2.
> debug(testF)
> testF(x,y)
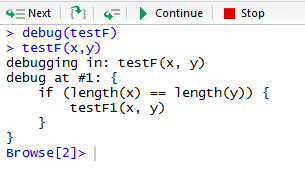
Vous avez maintenant accès au débogueur et pouvez accéder aux fonctions ou à la ligne suivante, comme le montre la figure 2.
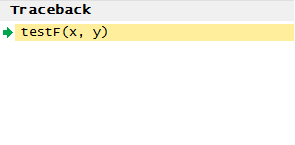
Il existe également un volet de suivi (Traceback) qui s'ouvre, ainsi qu'un volet de débogage spécifique (voir Figure 3).
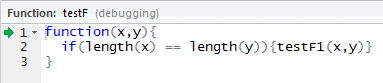
Cet exemple est, certes, pas particulièrement intéressant, mais l'important est de voir que RStudio est vraiment un outil unique pour vos besoins de script R.
IV. Comment vous améliorer ?▲
R est génial, mais vous rencontrerez souvent des situations où l'utilisation d'une boucle for sur un script est chronophage. Le listing 7 montre un exemple d'un tel script. Fondamentalement, il s'agit d'un ensemble de données géant contenant 1 000 000 d'enregistrements qui doivent être examinés et d'assigner des valeurs à une variable en fonction des valeurs des deux autres.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
df <- data.frame(Strings=sample(c("This","That","The Other"),1000000,replace=T),
Values=sample(c(0:4),1000000,replace=T),Result =
rep("DA",1000000))
for(i in 1:length(df[,1])){
if(df$Strings[i] == "This"){
if(df$Values[i] > 2){
df$Results[i] <- "CP"
next
}else{
df$Results[i] <- "QM"
}
}else if(df$Strings[i] == "That"){
df$Results[i] <- "BS"
next
}else if(df$Strings[i] == "The Other"){
if(df$Values[i] == 4){
df$Results[i] <- "FP"
next
}else{
df$Results[i] <- "DT"
}
}
}
Notez les instructions if imbriquées (lignes 7-10). l’imbrication à l'intérieur des boucles for est une tendance qui a vraiment bousillé les mécanismes dans R. Cette boucle peut prendre toute la nuit à s’exécuter, en fonction de votre matériel.
C'est ici que les fonctions interviennent. apply et toutes ses variantes : lapply, mapply, etc. permettent d’appliquer une même fonction aux lignes ou colonnes d'un objet semblable à une matrice. L’un des avantages de la fonction apply est la rapidité.
Le Listing 8 montre un exemple d’utilisation de la fonction apply. La fonction applyF prend la boucle for et la transforme en fonction. La fonction peut ensuite être appliquée à chaque ligne du tableau de données et les valeurs de retour sont stockées sous forme de liste dans les résultats. Une conversion rapide stocke les résultats dans le bon format des variables du tableau de données. Ce processus, qui effectue une tâche identique à celle de la boucle for, ne prend que quelques secondes.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
applyF <- function(vex){
if(vex[1] == "This"){
if(vex[2] > 2){
return("CP")
}else{
return("QM")
}
}else if(vex[1] == "That"){
return("BS")
}else if(vex[1] == "The Other"){
if(vex[2] == 4){
return("FP")
}else{
return("DT")
}
}
}
results <- apply(df,1,applyF)
df$Result <- factor(unlist(results))
Bien sûr, quelques secondes contre quelques heures, c'est une grosse différence. Le Listing 9 montre un résultat beaucoup plus rapide.
2.
3.
4.
5.
6.
7.
df2 <- data.frame(A=sample(as.character(c(1:100)),1000,replace=T),B=sample(as.
character(c(1:100)),1000,replace=T),
C=sample(as.character(c(1:100)),1000,replace=T),D=sample(as.character(c
(1:100)),1000,replace=T),
E=sample(as.character(c(1:100)),1000,replace=T),F=sample(as.character(c
(1:100)),1000,replace=T))
df2[,1:6] <- apply(df2,1,as.numeric)
Un autre avantage de la fonction apply est qu'elle simplifie le code. Ci-dessus, il existe une base de données composée d'entiers stockés en tant que caractères. Il y a plusieurs façons de convertir chaque variable. Vous pouvez les changer tous en nombres en utilisant apply et la fonction as.numeric. Vous pouvez ensuite effectuer une conversion volumineuse avec une courte ligne de code. Le dernier exemple est une utilisation plus commune de apply:
2.
3.
4.
vars <- apply(df2,2,var)
vars
A B C D E F
831.8953 810.2209 806.5781 854.8382 820.8769 866.8276
Si vous souhaitez connaître la variance de chaque variable dans le tableau de données, spécifiez simplement le tableau de données, l'index (dans ce cas, « 2 » pour les colonnes) et la fonction. L'affichage du résultat montre que vous avez maintenant les variances pour chaque colonne. Vous devez impérativement comprendre le fonctionnement de apply et de ses variantes si vous voulez être un utilisateur R efficace.
V. Les graphismes de base sont super, mais ggplot2 l'est aussi ▲
Avec le package de base de R, vous pouvez créer de superbes graphismes, mais une fois que vous ajoutez ggplot2 à votre répertoire, vous notez une nette amélioration. Regardons quelques exemples d'utilisation des graphiques de base ainsi que de ggplot2.
Le listing 10 est un script qui produit des images.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
library(ggplot2)
data(list=esoph)
barplot(xtabs(esoph$ncases~esoph$tobg+esoph$alcgp),beside=TRUE,col=rainbow(4)
,
main="Number of Cancer cases by Alcohol and Tobacco Use
Groups",xlab="Alcohol Use Group",ylab="Cases")
legend("topright",legend=levels(esoph$tobgp),fill=rainbow(4),title="Tobacco
Use Group")
ggplot(esoph,aes(x=alcgp,y=ncases,fill=tobgp))+
geom_bar(position="dodge",stat="identity")+
labs(fill="Tobacco Use Group",x="Acohol Use Group",y="Cases",title="Number
of Cancer cases by Alcohol and Tobacco Use Groups")
Les deux images sont géniales. Elles fournissent toutes les deux l'information nécessaire, mais la version gplot2 est plus esthétique.
Regardons un autre exemple. Le Listing 11 est un script qui compare des stocks allemands et suisses, montrant les résultats de base et avec ggplot2.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
EUst <- EuStockMarkets
plot(EUst[,1],ylab="Euros",main="German and Swiss Stock Time Series
Comparison")
lines(EUst[,2],col="Blue")
legend("topleft",legend=c("German","Swiss"),col=c("Black","Blue"),lty=1)
df <- data.frame(Year = as.double(time(EUst)),German=
as.double(EUst[,1]),Swiss = as.double(EUst[,2]))
ggplot(df,aes(x=Year))+
geom_line(aes(y=df$Swiss,col="Swiss"))+
geom_line(aes(y=df$German,col="German"))+
labs(color="",y="Euros",title="German and Swiss Stock Time Series
Comparison")
Encore une fois, il n'y a aucun problème avec les graphismes de base, qui sont meilleurs que les graphismes créés avec d’autres langages de programmation, mais la version ggplot2 est plus esthétique. De plus, la façon dont le graphe est créé avec ggplot est plus intuitive que la façon dont le graphe est créé en utilisant le package de base.
Le dernier exemple (Listing 12) montre comment ggplot2 vous permet un meilleur affichage des données qu’avec le package de base.
Intéressons-nous au jeu de données iris classique. Ici, vous pouvez voir les groupes de fleurs k-means en fonction de leurs attributs physiques, par rapport au groupe de la classification des espèces. Il y a trois espèces, donc vous avez trois groupes.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
iris <- iris
wssplot <- function(data, nc=15, seed=1234){
wss <- (nrow(data)-1)*sum(apply(data,2,var))
for (i in 2:nc){
set.seed(seed)
wss[i] <- sum(kmeans(data, centers=i)$withinss)
}
plot(1:nc, wss, type="b", xlab="Number of Clusters",
ylab="Within groups sum of squares")
}
fit <- kmeans(iris[,1:4], 3)
iris$Cluster <- fit$cluster
par(mfrow=c(1,2))
plot(iris$Sepal.Length,iris$Sepal.Width,col=iris$Cluster,pch=16,xlab="Sepal
Length",ylab="Sepal Width",
main="Iris Data Colored by Cluster")
legend("topright",legend=c(1:3),col=c(1:3),pch=16)
plot(iris$Sepal.Length,iris$Sepal.Width,col=iris$Species,pch=16,xlab="Sepal
Length",ylab="Sepal Width",
main="Iris Data Colored by Species")
legend("topright",legend=levels(iris$Species),col=c(1:3),pch=16)
par(mfrow=c(1,1))
ggplot(iris,aes(x=Sepal.Length,y=Sepal.Width))+
geom_point(aes(colour=Species))+
facet_grid(Cluster~.)+
labs(x="Sepal Length",y="Sepal Width",title="Iris Species-Cluster
Relationship")
Le graphique réalisé avec des packages de base montre que les espèces de setosa s'alignent avec le clustering. Cela montre aussi que le clustering n'identifie pas correctement les espèces versicolor et virgininica, mais nous n’avons pas plus d’informations.
Le graphe ggplot empile les graphes puis colore les points en fonction des espèces. Il est plus facile d'identifier la relation cluster-espèce versicolor-virginica et vous pouvez également voir pourquoi cela a pu se produire. Les plantes virginica qui ont été regroupées avec la mauvaise espèce ont une longueur plus courte (un sépale) que le reste des plantes virginica. Cela pourrait bien en être l'explication.
Les graphiques de base sont parfaits pour analyser les données lorsque vous ne vous souciez pas vraiment de leur apparence. L’utilisation de ggplot rendra vos données plus esthétiques lors de l’affichage.
VI. R est ce que vous voulez ou ce dont vous avez besoin▲
R peut faire beaucoup de choses que vous pourriez réserver pour un langage moins axé sur l'analyse des données. Le listing 13 est un exemple R utilisé de manière plus générale.
Cette requête utilise le HTTP. Les packages httr ont une fonction GET qui est juste une requête standard HTTP GET. L'API Google Places dispose de fonctionnalités HTTP dans lesquelles une URL spécifique fait passer la requête via une requête GET. L'URL est donnée sur les lignes 4 et 5 (ma clé n'est pas incluse, mais vous pouvez obtenir la vôtre de Google). Ensuite, à l'intérieur de la fonction qgoogle, la requête spécifique est construite sur les lignes 13-22, la requête GET est exécutée et les résultats sont analysés.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
23.
24.
25.
26.
27.
28.
29.
30.
31.
32.
33.
34.
35.
36.
37.
38.
39.
40.
41.
42.
43.
44.
45.
46.
47.
48.
49.
library('httr')
library('rjson')
library('stringr')
preamble <- 'https://maps.googleapis.com/maps/api/place/textsearch/json?'
key <- 'key=yourkeyhere'
for(i in 1:length(dataset[,1])) {
dataset[i,] <- tryCatch(qgoogle(dataset[i,]),
error = function(err){
print(paste("ERROR: ",err))
})
}
qgoogle <- function(vex){
name <- str_replace_all(vex$BUSINESS," ","+")
line_two <- str_replace_all(vex$BUSINESS2," ","+")
city <- str_replace_all(vex$CITY," ","+")
addr <- str_replace_all(vex$CLEANADDRE," ","+")
if(line_two == ""){
query <- paste(name,addr,city,state,sep="+")
}else{
query <- paste(name,line_two,addr,city,state,sep="+")
}
url <- paste(preamble,'&',"query=",query,'&',key,sep = "")
json.obj <- GET(url)
content <- content(json.obj)
if(content$status != "ZERO_RESULTS") {
vex$DATA <- TRUE
vex$DATA.WITH.ADDRESS <- TRUE
vex$NAME <- content$results[[1]]$name
vex$ADDR <- content$results[[1]]$formatted_address
vex$LAT <- content$results[[1]]$geometry$location$lat
vex$LONG <- content$results[[1]]$geometry$location$lng
if(length(content$results[[1]]$types) != 0){
vex$TYPE <- content$results[[1]]$types[[1]]
}
if(length(content$results[[1]]$permanently_closed) != 0){
vex$CLOSED <- "Permanently Closed"
}
} else {
vex$NAME <- NA
vex$ADDR <- NA
vex$LAT <- NA
vex$LONG <- NA
vex$TYPE <- NA
vex$CLOSED <- NA
vex$DATA <- FALSE
vex$DATA.WITH.ADDRESS <- FALSE
}
return(vex)
}
R n'est pas là pour remplacer d’autres langages de script, cependant, l'exemple ci-dessus montre que R peut faire plusieurs choses comme n'importe quel autre langage de script.
VII. Rcpp est plutôt génial ▲
Rcpp est un package qui permet l'importation de fonctions C ++ dans un script R. Voici un exemple standard d’utilisation d'une fonction C ++ dans R :
2.
3.
4.
5.
6.
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
int timesTwo(int x) {
return x * 2;
}
Cette fonction pourrait être créée dans R, mais l’objectif ici est de montrer qu'il est très simple de créer une fonction C++ puis de la déplacer dans votre environnement R. De plus, RStudio rend la gestion de ce logiciel beaucoup plus simple. Si vous avez besoin de faire quelque chose de sophistiqué et que vous pouvez le faire avec C++, vous pouvez facilement l'intégrer dans n'importe quel script R que vous désirez.
VIII. Résumé▲
Ce tutoriel n’est qu’une brève introduction au langage R, un aperçu de ce que vous devez savoir quand vous programmez en R. Ces sept choses sont absolument importantes, et vous feront gagner du temps et éviter des maux de tête lorsque vous commencerez à utiliser R.