


IX. CHAPITRE 9 Focus sur la visualisation graphique▲
Objectifs
Ce chapitre est une mise au point sur la visualisation graphique avec R. Il traite de l'exportation des tableaux et des graphiques, il présente la gestion des couleurs et il introduit, en préambule au chapitre sur la cartographie, la manipulation du package ggplot2.
Avertissement
Ce chapitre sur la visualisation et la couleur est destiné à être imprimé en noir et blanc, le code utilisé est reproduit, mais les sorties graphiques sont rarement affichées. C'est également cette contrainte éditoriale qui amène, dans l'ensemble du manuel, à ne pas toujours respecter les règles de sémiologie graphique concernant les couleurs (cf. Section 9.2Gestion des couleurs).
Prérequis
Types d'objet présentés dans le Chapitre 2CHAPITRE 2 Prise en main et manipulation des données ; graphiques présentés dans le Chapitre 4CHAPITRE 4 Analyse univariée et le Chapitre 5CHAPITRE 5 Analyse bivariée. Notions de sémiologie graphique.
Description des packages utilisés
Plusieurs packages sont proposés pour l'exportation des tableaux et la création dynamique de contenus : tables pour exporter des tableaux dans des tableurs, xtable pour exporter les tableaux au format LATEX et knitr pour produire des documents dynamiques.
La représentation graphique demande également une manipulation de palettes de couleurs. Il existe aussi des packages spécialisés dans ce domaine, en particulier RColorBrewer.
Plusieurs packages spécialisés dans la représentation graphique sont disponibles. Les deux principaux packages graphiques généralistes sont lattice et ggplot2, d'autres proposent des fonctions spécifiques, comme le package vcd pour la visualisation de variables qualitatives. C'est ggplot2 qui est présenté ici, pour les raisons détaillées par la suite.
Description des données utilisées
Les applications présentées dans ce chapitre sont effectuées sur les données historiques contenues dans le package HistData déjà utilisé à la Section 3.4L'application de fonctions sur des ensembles : les données de « statistique morale » d'André-Michel Guerry et les données sur le choléra de John Snow. Les premières comprennent un ensemble de variables touchant à la « moralité » comme le nombre de suicides, de prostituées ou de désertions dans les départements français vers 1830. Les secondes présentent des données spatialisées sur l'épidémie de choléra à Londres dans les années 1850. Les travaux de Guerry et ceux de Snow sont d'une importance majeure dans l'histoire de la statistique et de l'épidémiologie, ce pour quoi leurs jeux de données ont été mis à disposition par Michael Friendly et Stéphane Dray(26).
IX-A. Exportation des tableaux et des graphiques▲
L'utilisateur peut visualiser des résultats numériques et graphiques dans l'environnement RStudio, mais il a souvent besoin d'exporter ces sorties pour les intégrer dans des documents rédigés. Plusieurs cas sont envisagés dans le tableau qui suit, selon le type de sortie (tableau ou image) et le mode de travail, en particulier le logiciel utilisé pour produire du contenu.
Deux types de flux de travail (workflow) peuvent être distingués. Le plus classique consiste à découpler l'écriture du texte et la production des sorties numériques ou graphiques : l'utilisateur produit un graphique avec R, l'exporte dans un format d'image et l'insère dans un logiciel de traitement de texte avec lequel il écrit le contenu. L'autre façon de procéder, de plus en plus développée, s'inscrit dans la vague de la reproducible research. Elle consiste à combiner l'écriture des contenus textuels et des traitements numériques et graphiques pour générer un document tout-en-un. Ce flux de travail est souvent qualifié de dynamic report generation.
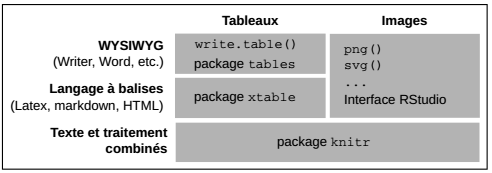
Si la sortie est un tableau et que le document est rédigé sur un traitement de texte de type WYSIWYG (What You See Is What You Get) tel que LibreOffice Writer ou MS Word, il faut nécessairement passer par une exportation dans un tableur avec les fonctions write.table() présentées dans le premier chapitre. Le package tables, avec ses fonctions tabular() et write.table.tabular(), facilite ce travail.
Si la sortie est un tableau et que le document est rédigé avec un langage à balises - LaTeX, markdown ou HTML - le package xtable propose une fonction éponyme xtable() qui transforme le tableau en code directement utilisable dans le document rédigé. Dans cet exemple, un tableau de dénombrement des départements selon la variable Region est exporté au format LaTeX :
2.
3.
4.
5.
library(xtable)
library(HistData)
data(Guerry)
xtable(table(Guerry$Region))
Si la sortie est une image (graphique ou carte), elle peut être exportée via l'interface graphique de RStudio. Dans l'onglet Plots plusieurs options d'exportation des graphiques sont proposées : il est possible de fixer la taille de l'image et de choisir parmi plusieurs formats courants, par exemple svg, png ou pdf. Pour plus de précision dans les réglages et/ou pour intégrer l'exportation dans le script, il faut utiliser les fonctions graphiques qui prennent le nom du format à produire : png(), svg(), jpeg(), etc. Ces fonctions initialisent le dispositif graphique, il doit ensuite être fermé par la fonction dev.off(). L'exemple suivant exporte un fichier png qui contient l'histogramme de la variable Crime_pers.
2.
3.
png(filename = "chemin/fichier.png")
hist(Guerry$Crime_pers)
dev.off()
Dans la fonction png(), l'utilisateur peut fixer une taille (arguments width et height) dans une unité de longueur (units) comme les pouces ou les centimètres, il peut également préciser la résolution en ppi (pixels per inch, pixels par pouce) pour obtenir une taille en termes de nombre de pixels. L'utilisateur peut aussi fixer directement la taille en pixels en utilisant ces trois arguments. Enfin, l'argument pointsize est une mesure relative de la taille des caractères en fonction de la résolution.
Dans ce flux de travail, la meilleure façon d'obtenir des images prêtes à l'emploi est de les paramétrer le mieux possible avec R, de les exporter au format svg et éventuellement de les retoucher sur un logiciel de dessin vectoriel comme Inkscape.
Pour produire un document qui fourmille de traitements et de graphiques, l'arme ultime est la combinaison de l'écriture et des traitements dans un même document. R et RStudio disposent d'outils très pratiques pour cela grâce au package knitr(27). Dans l'interface de RStudio, le menu File > New file propose plusieurs solutions : R Sweave pour une combinaison avec LATEX (ce manuel est écrit de la sorte), R Markdown, R HTML et R Presentation pour produire des documents écrits en markdown et en HTML. À la date d'écriture de ce manuel, la version de RStudio la plus récente permet d'écrire un document en markdown et de compiler le texte et le code pour obtenir une sortie en pdf, en HTML et en docx (Microsoft Word).
IX-B. Gestion des couleurs▲
Sans rentrer dans le détail du codage des couleurs pour l'impression et la visualisation numérique, il faut simplement mentionner que plusieurs conventions existent : le code RGB (red green blue, RVB en français) qui indique le mélange des trois couleurs primaires pour obtenir une couleur donnée ; le code CMYK (cyan, magenta, yellow, key, CMJN en français) issu du monde de l'imprimerie ; le code hexadécimal issu des standards des navigateurs Internet.
Avec R, tous ces codes peuvent être utilisés en cas de contrainte éditoriale forte, mais il s'agit rarement de la méthode la plus simple. Le plus courant est d'assigner des couleurs prédéfinies. Pour obtenir l'ensemble des couleurs disponibles, il faut exécuter la fonction colors(). Cette fonction renvoie une liste de 657 couleurs prédéfinies(28).
Les couleurs peuvent d'abord être désignées par leur nom :
2.
3.
4.
5.
colors()
hist(Guerry$Crime_pers, col = "red", border = "green")
hist(Guerry$Crime_pers,
col = "springgreen",
border = "darksalmon")
Les couleurs peuvent aussi être désignées par leur numéro dans le vecteur de 657 couleurs renvoyé par la fonction colors(). Ainsi, les deux lignes suivantes sont équivalentes :
2.
3.
4.
5.
hist(Guerry$Crime_pers,
col = colors()[ 26],
border = colors()[ 133])
hist(Guerry$Crime_pers, col = "blue", border = "firebrick")
Les couleurs peuvent être désignées par leur code hexadécimal :
2.
3.
hist(Guerry$Crime_pers,
col = "#FF0000",
border = "#FFAA00")
Enfin, R dispose de palettes de couleurs prédéfinies, par exemple rainbow() ou heat.colors(). Ces fonctions demandent comme argument le nombre de couleurs à extraire de la palette et renvoient le code hexadécimal correspondant :
rbPal <- rainbow(n = 5)
boxplot(Guerry$Crime_pers ~ Guerry$Region, col = rbPal)Certains packages proposent des palettes de couleurs supplémentaires, le plus connu étant RColorBrewer qui est une implémentation des palettes de couleurs créées par Cynthia Brewer(29). Ce package contient des palettes avec des variations de couleurs et de valeurs adaptées à trois grands types de variables statistiques : des variables continues, des variables continues avec une valeur seuil, des variables qualitatives.
Pour les premières, la variation statistique est traduite visuellement par une montée en valeur sur une même couleur, du vert clair au vert foncé par exemple. Pour les deuxièmes, la variation statistique est traduite par une montée en valeur sur deux couleurs distinctes divisées autour d'un seuil. Cette palette dite « divergente » est efficace pour représenter par exemple un solde qui prend des valeurs négatives et positives, les valeurs négatives seront traduites dans une couleur froide (bleu par exemple) et les positives dans une couleur chaude (rouge par exemple). Enfin, les variables qualitatives sont représentées par une variation de couleur.
Toute carte statistique devrait suivre ces règles sémiologiques simples qui établissent des liens cohérents entre la variation statistique d'un caractère et la variation visuelle représentée sur la carte. Ces règles sont difficiles à respecter lorsqu'on ne dispose que de niveaux de gris, c'est pourquoi plusieurs cartes produites dans ce manuel sont signalées en note de bas de page comme ne respectant pas les règles qui viennent d'être énoncées.
Voici le code pour afficher l'ensemble des palettes disponibles, pour afficher seulement un certain type de palette (divergente dans ce cas) et pour créer une palette de n couleurs (6 dans ce cas).
2.
3.
4.
library(RColorBrewer)
display.brewer.all()
display.brewer.all(type = "div")
pastelPal <- brewer.pal(n = 6, name = "Pastel2")
Le package RColorBrewer est utilisé par défaut pour les représentations graphiques produites avec ggplot2, package présenté dans la section qui suit.
IX-C. Introduction à ggplot2▲
IX-C-1. Intérêt vis-à-vis des fonctions graphiques classiques▲
C'est ggplot2 qui est présenté ici pour plusieurs raisons. D'abord, il s'agit du package graphique le plus polyvalent et le plus utilisé, c'est d'ailleurs l'un des packages les plus téléchargés sur l'ensemble des packages disponibles sur le CRAN. Ensuite, ce package est conçu comme l'implémentation d'une « grammaire graphique » : il s'appuie donc sur une base théorique robuste qui systématise le passage des attributs statistiques d'un tableau aux attributs esthétiques d'une représentation graphique. Enfin, il est développé par Hadley Wickham, l'un des développeurs les plus productifs de la communauté R : il a vocation à s'étendre et à communiquer avec d'autres packages, en particulier dans le domaine de la visualisation interactive et de la cartographie.
Le package ggplot2 est décrit dans la plupart des manuels de visualisation avec R, il est présenté en détail dans un manuel dédié, il dispose enfin d'un site web dédié(30). L'avantage de ce package est qu'il permet une manipulation fine des attributs esthétiques. Les fonctions graphiques de base, utilisées dans les chapitres précédents, sont simples et rapides : boxplot() et hist() permettent par exemple de faire des boîtes à moustaches et des histogrammes, de modifier quelques paramètres comme la couleur ou la taille. Cependant, leur domaine d'utilisation est limité à ces quelques paramétrages.
Avec ggplot2, il est possible de produire tous types de graphiques, pas seulement les grands classiques. On peut produire de nouveaux types de représentations graphiques ou encore reproduire des graphiques uniques : celui de Minard par exemple (cf. Figure 3.4)(31), certains graphiques oubliés proposés par Tufte comme le slopegraph par exemple.
IX-C-2. Aperçu de la syntaxe▲
La polyvalence de ggplot2 est possible parce qu'il permet un travail fin sur les éléments suivants, constitutifs d'une représentation graphique :
- variable visuelle (mappings) : variation esthétique correspondant à la variation statistique, en particulier la taille et la couleur des éléments ;
- géométrie (geoms) : implantation géométrique des objets graphiques, principalement des points, des lignes et des polygones ;
- échelle (scales) : variation dans l'espace des valeurs numériques mise à l'échelle dans l'espace des variables visuelles ;
- système de coordonnées (coord) : projection des valeurs sur le plan, par exemple avec un système de coordonnées cartésien, polaire ou un système de projection cartographique ;
- transformation statistique (stats) : élément optionnel, il est utile par exemple pour représenter graphiquement des résumés numériques (fréquences absolues ou relatives) ;
- construction d'une planche (facet) : élément optionnel, il est utile pour construire une planche constituée de plusieurs graphiques correspondant à des sous-groupes de données.
Pour utiliser ggplot2, il faut d'abord se familiariser avec une syntaxe et un fonctionnement particuliers. D'abord, les données statistiques à graphier doivent nécessairement être contenues dans un objet de type data.frame. Ensuite, à la différence de la plupart des fonctions graphiques de base, ggplot2 peut créer un objet qui contient les données et les paramétrages graphiques. Pour échanger un graphique classique produit avec plot() par exemple, il faut mettre à disposition à la fois le code de la représentation graphique et les données nécessaires. L'objet ggplot2, en revanche, est autonome, il peut être stocké et échangé.
Pour créer un tel objet, le package propose une fonction de base ggplot() à laquelle on ajoute les différents éléments décrits ci-dessus à l'aide de l'opérateur +. Voici un exemple fictif qui produirait un nuage de points. Les données sont stockées dans un data.frame nommé mydata, ces données sont représentées par des points dont les coordonnées sont fixées par deux variables quantitatives x et y. Enfin, la taille et la couleur des points peuvent varier en fonction d'autres variables présentes dans le tableau.
2.
3.
4.
5.
6.
7.
8.
9.
# CAS 1
ggplot(mydata) +
geom_point(aes(x = , y = , size = , color = )) +
scale_size(...)
scale_color(…)
# CAS 2
ggplot(mydata) +
geom_point(aes(x = , y = ), size = , color = )
La différence entre le premier et le second cas est le statut de la taille et de la couleur. Dans le premier, les arguments sont inclus dans la fonction aes() (aesthetics mapping). La taille et la couleur sont donc considérées comme des variables visuelles : elles vont traduire une variation statistique par une variation visuelle et cette variation sera mise à l'échelle - échelle de taille et de couleur - par les fonctions de type scale().
Dans le second cas, l'utilisateur fixe une couleur et une taille pour l'ensemble des points : il ne s'agit plus de variables visuelles, mais de paramètres graphiques d'ensemble. Dans ce cas, les fonctions de type scale() ne sont pas utiles.
IX-C-3. Variables visuelles▲
Cet exemple produit un nuage de points mettant en relation la variable Prostitutes, qui le nombre de prostituées à Paris par département de naissance, et la variable Distance, qui indique la distance du département à Paris.
|
Sélectionnez 1. 2. 3. 4. 5. |
|
|
|
Sélectionnez 1. 2. 3. |
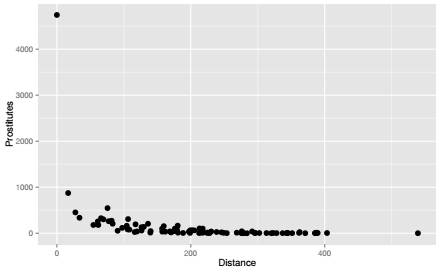
L'objet créé est de type ggplot, on peut accéder à son contenu, en particulier aux données, avec l'opérateur $ comme pour les objets de type list et data.frame. La taille et la couleur sont des paramètres d'ensemble et non des variables visuelles. Le thème par défaut présente un fond gris clair carroyé de lignes blanches, les lignes principales sont fixées avec un pas de 200 pour l'axe des x et un pas de 1000 pour l'axe des y, le titre des axes est le nom de variables représentées. Tous ces paramètres peuvent bien sûr être modifiés.
D'un point de vue thématique, la variable Prostitutes indique le nombre de prostituées à Paris par département de naissance. Ce nombre décroît avec la distance à Paris selon une fonction exponentielle négative, résultat cohérent avec les modèles d'interaction spatiale développés dans le domaine de la géographie et de la démographie des migrations.
L'exemple qui suit est un nuage de points mettant en relation les crimes contre la personne et les crimes contre la propriété. Ces deux variables sont exprimées en population par crime, c'est-à-dire l'inverse de tous les taux calculés de nos jours, par exemple un taux de criminalité exprimé en crimes par population. Le thème par défaut peut être substitué par un thème plus sobre : chaque élément du thème peut être paramétré, la couleur du cadre, l'épaisseur des lignes, etc., mais il est plus facile d'utiliser des thèmes tout faits, par exemple le thème theme_bw().
La taille et la couleur sont utilisées comme variables visuelles : la taille traduit le nombre total de crimes, variable calculée au préalable, et la couleur traduit la région (Nord, Sud, Est, Ouest, Centre)(32). La valeur de la Corse est modifiée et la région Sud lui est assignée.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. 16. |
|
|
|
Sélectionnez 1. 2. 3. 4. |
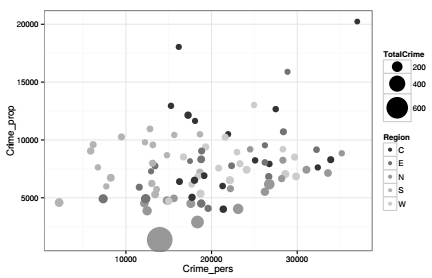
Le graphique fait apparaître de fortes disparités entre ces deux types de crimes ainsi qu'une relation presque inexistante entre les deux. Les deux variables visuelles renseignent sur le nombre absolu de crimes commis (taille), le département de Seine en tête avec 751 crimes, et sur les grandes régions correspondant aux départements (couleur).
IX-C-4. Construction d'une planche▲
Il est souvent utile de faire construire des planches de graphiques ou de cartes, c'est-à-dire d'inclure dans une même sortie graphique un ensemble de cartes ou de graphiques correspondant à des sous-groupes de données. Ce sont les fonctions facet_grid et facet_wrap qui permettent cela, fonctions dites de « maillage » (latticing). Dans cet exemple, on cherche à produire un nuage de points similaire au précédent, mais en différenciant chaque région.
|
Sélectionnez 1. 2. 3. 4. 5. 6. |
|
|
|
Sélectionnez 1. 2. 3. 4. |
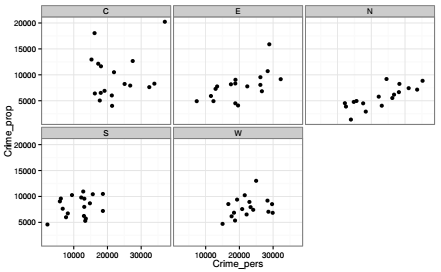
Les deux axes x et y se mettent par défaut à la même échelle, ce qui facilite la comparaison des données entre tous les sous-groupes. Ce paramètre peut bien sûr être modifié.
IX-C-5. Variables de regroupement▲
Dans les deux exemples précédents, la variable de regroupement Region a été utilisée de deux façons différentes, comme variable visuelle pour colorer les points et comme variable de désagrégation pour construire une planche.
L'application introduit l'usage de ggplot2 pour la cartographie. Deux points essentiels sont abordés : l'utilisation d'une variable de regroupement pour construire des objets à représenter et l'utilisation des systèmes de coordonnées. Un exemple très simple pour commencer : le tableau suivant contient quatre points avec leurs coordonnées et trois variables de regroupement, verti, horiz et polyg.
En utilisant la variable verti, on signale qu'il faut regrouper les points P1-P2 et P3-P4 pour former des segments, ce qui se traduit par deux segments verticaux. Avec la variable horiz, ce sont les points P1-P3 et P2-P4 qui sont regroupés formant deux segments horizontaux.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
geomEx <- data.frame(id = c("P1", "P2", "P3", "P4"),
coordx = c(1, 1, 2, 2),
coordy = c(1, 2, 2, 1),
verti = c("S1", "S1", "S2", "S2"),
horiz = c("S1", "S2", "S1", "S2"),
polyg = rep("POL", 4))
ggplot(geomEx) +
geom_line(aes(x = coordx, y = coordy, group = verti)) +
theme_bw()
ggplot(geomEx) +
geom_line(aes(x = coordx, y = coordy, group = horiz)) +
theme_bw()
La géométrie geom_polygon() fonctionne de même : elle prend comme argument une liste de points avec leurs coordonnées et une variable de regroupement qui indique quels points doivent être reliés pour former les polygones.
2.
3.
4.
5.
6.
ggplot(geomEx) +
geom_polygon(aes(x = coordx,
y = coordy,
group = polyg),
fill = "red") +
theme_bw()
Ce travail est maintenant effectué sur de véritables données spatialisées, celles de John Snow qui indiquent la localisation des morts de choléra recensés en 1854 autour de Broad Street. Le tableau Snow.deaths est composé de 578 points avec leurs coordonnées et le tableau Snow.streets donne la localisation des rues. Ces rues sont des segments composés de points : les champs x et y donnent leurs coordonnées, le champ street indique quels points il faut relier pour former les segments. Dans ce cas, les données nécessaires pour représenter la carte sont contenues dans deux objets différents. Ces objets sont donnés comme argument dans la fonction geom_ et non dès la fonction ggplot().
La fonction coord_equal() est utile dans la production de cartes : elle force la sortie graphique à respecter un ratio fixe de correspondance entre l'échelle des x et l'échelle des y. Par défaut, ce ratio est de 1, ce qui force à respecter un ratio de 1 pour 1. C'est le ratio qui sera toujours utilisé en cartographie, mais d'autres ratios seraient paramétrables.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. |
|
|
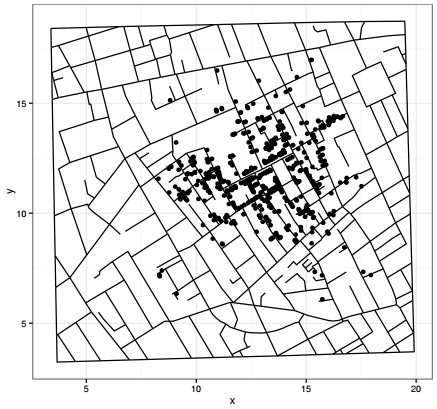
Les trois géométries qui viennent d'être présentées, geom_point(), geom_path() et geom_polygon(), constituent la base permettant de produire des cartes avec ggplot2. Elles seront utiles pour cartographier les trois grands types d'implantation d'objets géographiques : implantations ponctuelle, linéaire et zonale. À l'issue de ce chapitre, l'utilisateur dispose de tous les éléments pour produire des sorties graphiques de qualité, pour bien gérer les palettes de couleurs et pour exporter ces sorties dans différents formats. Ces bases seront utiles pour aborder le chapitre de cartographie, tout en gardant à l'esprit que les règles de sémiologie graphique ne peuvent pas toujours être respectées en ce qui concerne les palettes de couleur vu la contrainte éditoriale d'édition en noir et blanc.