 R pour les sociologues (et assimilés)
R pour les sociologues (et assimilés)



Partie 3 Premier travail avec des données▲
Regrouper les commandes dans des scripts▲
Jusqu'à maintenant nous avons utilisé uniquement la console pour communiquer avec R via l'invite de commandes. Le principal problème de ce mode d'interaction est qu'une fois qu'une commande est tapée, elle est pour ainsi dire « perdue », c'est-à-dire que l'on doit la saisir à nouveau si on veut l'exécuter une seconde fois. L'utilisation de la console est donc restreinte aux petites commandes « jetables », le plus souvent utilisées comme test.
La plupart du temps, les commandes seront stockées dans un fichier à part, que l'on pourra facilement ouvrir, éditer et exécuter en tout ou partie si besoin. On appelle en général ce type de fichier un script.
Pour comprendre comment cela fonctionne, dans le menu Fichier, sélectionnez l'entrée Nouveau script(7). Une nouvelle fenêtre (vide) apparaît. Nous pouvons désormais y saisir des commandes. Par exemple, tapez sur la première ligne la commande suivante :
2+2Ensuite, allez dans le menu Édition, et choisissez Exécuter la ligne ou sélection. Apparemment rien ne se passe, mais si vous jetez un œil à la fenêtre de la console, les lignes suivantes ont dû faire leur apparition :
R> 2 + 2
[1] 4Voici donc comment soumettre rapidement à R les commandes saisies dans votre fichier. Vous pouvez désormais l'enregistrer, l'ouvrir plus tard, et en exécuter tout ou partie. À noter que vous avez plusieurs possibilités pour soumettre des commandes à R :
- vous pouvez exécuter la ligne sur laquelle se trouve votre curseur en sélectionnant Édition puis Exécuter la ligne ou Sélection, ou plus simplement en appuyant simultanément sur les touches Ctrl et R(8) ;
- vous pouvez sélectionner plusieurs lignes contenant des commandes et les exécuter toutes, en une seule fois, exactement de la même manière ;
- vous pouvez exécuter d'un coup l'intégralité de votre fichier en choisissant Édition puis Exécuter tout.
La majorité du travail sous R consistera donc à éditer un ou plusieurs fichiers de commandes et à envoyer régulièrement les commandes saisies à R en utilisant les raccourcis clavier ad hoc.
Ajouter des commentaires▲
Un commentaire est une ligne ou une portion de ligne qui sera ignorée par R. Ceci signifie que l'on peut y écrire ce que l'on veut, et que l'on va tout utiliser pour ajouter tout un tas de commentaires à notre code permettant de décrire les différentes étapes du travail, les choses à se rappeler, les questions en suspens, etc.
Un commentaire sous R commence par un ou plusieurs symboles # (qui s'obtient avec les touches <Alt Gr> et <3> sur les claviers de type PC). Tout ce qui suit ce symbole jusqu'à la fin de la ligne est considéré comme un commentaire. On peut créer une ligne entière de commentaire, par exemple en la faisant débuter par ## :
## Tableau croisé de la CSP par le nombre de livres lus
## Attention au nombre de non-réponses !On peut aussi créer des commentaires pour une ligne en cours :
x <- 2 # On met 2 dans x, parce qu'il le vaut bienDans tous les cas, il est très important de documenter ses fichiers R au fur et à mesure, faute de quoi on risque de ne plus y comprendre grand-chose, si on les reprend ne serait-ce que quelques semaines plus tard.
Tableaux de données▲
Dans cette partie nous allons utiliser un jeu de données inclus dans l'extension rgrs. Cette extension et son installation sont décrites dans la partie B.3B.3 L'extension rgrs(9).
Le jeu de données en question est un extrait de l'enquête Histoire de vie réalisée par l'INSEE en 2003. Il contient 2000 individus et 20 variables. Le descriptif des variables est indiqué dans l'annexe B.3.3B.3.3 Le jeu de données hdv2003.
Pour pouvoir utiliser ces données, il faut d'abord charger l'extension rgrs (après l'avoir installée, bien entendu) :
R> library(rgrs)Puis indiquer à R que nous souhaitons accéder au jeu de données à l'aide de la commande data :
R> data(hdv2003)Bien. Et maintenant, elles sont où mes données ? Et bien, elles se trouvent dans un objet nommé hdv2003 désormais accessible directement. Essayons de taper son nom à l'invite de commande :
R> hdv2003Le résultat (non reproduit ici) ne ressemble pas forcément à grand-chose… Il faut se rappeler que par défaut, lorsqu'on lui fournit seulement un nom d'objet, R essaye de l'afficher de la manière la meilleure (ou la moins pire) possible. La réponse à la commande hdv2003 n'est donc rien moins que l'affichage des données brutes contenues dans cet objet.
Ce qui signifie donc que l'intégralité de notre jeu de données est incluse dans l'objet nommé hdv2003 ! En effet, dans R, un objet peut très bien contenir un simple nombre, un vecteur ou bien le résultat d'une enquête tout entier. Dans ce cas, les objets sont appelés des data frames, ou tableaux de données. Ils peuvent être manipulés comme tout autre objet. Par exemple :
R> d <- hdv2003va entraîner la copie de l'ensemble de nos données dans un nouvel objet nommé d, ce qui peut paraître parfaitement inutile, mais a en fait l'avantage de fournir un objet avec un nom beaucoup plus court, ce qui diminuera la quantité de texte à saisir par la suite.
Résumons : comme nous avons désormais décidé de saisir nos commandes dans un script et non plus directement dans la console, les premières lignes de notre fichier de travail sur les données de l'enquête Histoire de vie, pourraient donc ressembler à ceci :
2.
3.
4.
5.
6.
## Chargement des extensions nécessaires
library(rgrs)
## Jeu de données hdv2003
data(hdv2003)
d <- hdv2003
Inspecter les données▲
Structure du tableau▲
Avant de travailler sur les données, nous allons essayer de voir à quoi elles ressemblent. Dans notre cas il s'agit de se familiariser avec la structure du fichier. Lors de l'import de données depuis un autre logiciel, il s'agira souvent de vérifier que l'importation s'est bien déroulée.
Les fonctions nrow, ncol et dim donnent respectivement le nombre de lignes, le nombre de colonnes et les dimensions de notre tableau. Nous pouvons donc d'ores et déjà vérifier que nous avons bien 2000 lignes et 20 colonnes :
2.
3.
4.
5.
6.
R> nrow(d)
[1] 2000
R> ncol(d)
[1] 20
R> dim(d)
[1] 2000 20
La fonction names donne les noms des colonnes de notre tableau, c'est-à-dire les noms des variables :
2.
3.
4.
5.
6.
R> names(d)
[1] "id" "age" "sexe" "nivetud"
[5] "poids" "occup" "qualif" "freres.soeurs"
[9] "clso" "relig" "trav.imp" "trav.satisf"
[13] "hard.rock" "lecture.bd" "peche.chasse" "cuisine"
[17] "bricol" "cinema" "sport" "heures.tv"
La fonction str est plus complète. Elle liste les différentes variables, indique leur type et donne le cas échéant des informations supplémentaires ainsi qu'un échantillon des premières valeurs prises par cette variable :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
22.
R> str(d)
'data.frame': 2000 obs. of 20 variables:
$ id : int 1 2 3 4 5 6 7 8 9 10 ...
$ age : int 28 23 59 34 71 35 60 47 20 28 ...
$ sexe : Factor w/ 2 levels "Homme","Femme": 2 2 1 1 2 2 2 1 2 1 ...
$ nivetud : Factor w/ 8 levels "N'a jamais fait d'etudes",..: 8 NA 3 8 3 6 3 6 NA 7 ...
$ poids : num 2634 9738 3994 5732 4329 ...
$ occup : Factor w/ 7 levels "Exerce une profession",..: 1 3 1 1 4 1 6 1 3 1 ...
$ qualif : Factor w/ 7 levels "Ouvrier specialise",..: 6 NA 3 3 6 6 2 2 NA 7 ...
$ freres.soeurs: int 8 2 2 1 0 5 1 5 4 2 ...
$ clso : Factor w/ 3 levels "Oui","Non","Ne sait pas": 1 1 2 2 1 2 1 2 1 2 ...
$ relig : Factor w/ 6 levels "Pratiquant regulier",..: 4 4 4 3 1 4 3 4 3 2 ...
$ trav.imp : Factor w/ 4 levels "Le plus important",..: 4 NA 2 3 NA 1 NA 4 NA 3 ...
$ trav.satisf : Factor w/ 3 levels "Satisfaction",..: 2 NA 3 1 NA 3 NA 2 NA 1 ...
$ hard.rock : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 1 1 1 1 ...
$ lecture.bd : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 1 1 1 1 ...
$ peche.chasse : Factor w/ 2 levels "Non","Oui": 1 1 1 1 1 1 2 2 1 1 ...
$ cuisine : Factor w/ 2 levels "Non","Oui": 2 1 1 2 1 1 2 2 1 1 ...
$ bricol : Factor w/ 2 levels "Non","Oui": 1 1 1 2 1 1 1 2 1 1 ...
$ cinema : Factor w/ 2 levels "Non","Oui": 1 2 1 2 1 2 1 1 2 2 ...
$ sport : Factor w/ 2 levels "Non","Oui": 1 2 2 2 1 2 1 1 1 2 ...
$ heures.tv : num 0 1 0 2 3 2 2.9 1 2 2 ...
La première ligne nous informe qu'il s'agit bien d'un tableau de données avec 2000 observations et 20 variables. Vient ensuite la liste des variables. La première se nomme id et est de type nombre entier (int). La seconde se nomme age et est de type numérique. La troisième se nomme sexe, il s'agit d'un facteur (factor).
Un facteur et une variable pouvant prendre un nombre limité de modalités (levels). Ici notre variable a deux modalités possibles : Homme et Femme. Ce type de variable est décrit plus en détail section 5.1.3Facteurs.
Inspection visuelle▲
La particularité de R par rapport à d'autres logiciels comme Modalisa ou SPSS est de ne pas proposer, par défaut, de vue des données sous forme de tableau. Ceci peut parfois être un peu déstabilisant dans les premiers temps d'utilisation, même si on perd vite l'habitude et que l'on finit par se rendre compte que « voir » les données n'est pas forcément un gage de productivité ou de rigueur dans le traitement.
Néanmoins, R propose une visualisation assez rudimentaire des données sous la forme d'une fenêtre de type tableur, via la fonction edit :
R> edit(d)
La fenêtre qui s'affiche permet de naviguer dans le tableau, et même d'éditer le contenu des cases et donc de modifier les données. Lorsque vous fermez la fenêtre, le contenu du tableau s'affiche dans la console : il s'agit en fait du tableau comportant les éventuelles modifications effectuées, d restant inchangé.
Si vous souhaitez appliquer ces modifications, vous pouvez le faire en créant un nouveau tableau :
R> d.modif <- edit(d)
ou en remplaçant directement le contenu de d(10) :
R> d <- edit(d)
La fonction edit peut être utile pour un avoir un aperçu visuel des données, par contre, il est très fortement déconseillé de l'utiliser pour modifier les données. Si on souhaite effectuer des modifications, on remonte en général aux données originales (retouches ponctuelles dans un tableur, par exemple) ou on les effectue à l'aide de commandes (qui seront du coup reproductibles).
Accéder aux variables▲
d représente donc l'ensemble de notre tableau de données. Nous avons vu que si l'on saisit simplement d à l'invite de commandes, on obtient un affichage du tableau en question. Mais comment accéder aux variables, c'est-à-dire aux colonnes de notre tableau ?
La réponse est simple : on utilise le nom de l'objet, suivi de l'opérateur $, suivi du nom de la variable, comme ceci :
2.
3.
4.
5.
6.
7.
8.
9.
10.
R> d$sexe
[1] Femme Femme Homme Homme Femme Femme Femme Homme Femme Homme Femme
[12] Homme Femme Femme Femme Femme Homme Femme Homme Femme Femme Homme
[23] Femme Femme Femme Homme Femme Homme Homme Homme Homme Homme Homme
[34] Homme Femme Femme Homme Femme Femme Homme Femme Homme Homme Femme
[45] Femme Homme Femme Femme Femme Femme Homme Femme Homme Femme Homme
[56] Femme Femme Femme Homme Femme Femme Homme Homme Homme Homme Femme
[67] Homme Homme Femme Femme
[ reached getOption("max.print") -- omitted 1930 entries ]]
Levels: Homme Femme
On constate alors que R a bien accédé au contenu de notre variable sexe du tableau d et a affiché son contenu, c'est-à-dire l'ensemble des valeurs prises par la variable.
Les fonctions head et tail permettent d'afficher seulement les premières (respectivement les dernières) valeurs prises par la variable. On peut leur passer en argument le nombre d'éléments à afficher :
2.
3.
4.
5.
R> head(d$sport)
[1] Non Oui Oui Oui Non Oui
Levels: Non Oui
R> tail(d$age, 10)
[1] 52 42 50 41 46 45 46 24 24 66
À noter que ces fonctions marchent aussi pour afficher les lignes du tableau d :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
R> head(d, 2)
id age sexe nivetud
1 1 28 Femme Enseignement superieur y compris technique superieur
2 2 23 Femme <NA>
poids occup qualif freres.soeurs clso
1 2634.398 Exerce une profession Employe 8 Oui
2 9738.396 Etudiant, eleve <NA> 2 Oui
relig trav.imp trav.satisf hard.rock
1 Ni croyance ni appartenance Peu important Insatisfaction Non
2 Ni croyance ni appartenance <NA> <NA> Non
lecture.bd peche.chasse cuisine bricol cinema sport heures.tv
1 Non Non Oui Non Non Non 0
2 Non Non Non Non Oui Oui 1
Analyser une variable▲
Variable quantitative▲
Principaux indicateurs
Comme la fonction str nous l'a indiqué, notre tableau d contient plusieurs valeurs numériques, dont la variable heures.tv qui représente le nombre moyen passé par les enquêtés à regarder la télévision quotidiennement. On peut essayer de déterminer quelques caractéristiques de cette variable, en utilisant des fonctions déjà vues précédemment :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
R> mean(d$heures.tv)
[1] NA
R> mean(d$heures.tv, na.rm = TRUE)
[1] 2.246566
R> sd(d$heures.tv, na.rm = TRUE)
[1] 1.775853
R> min(d$heures.tv, na.rm = TRUE)
[1] 0
R> max(d$heures.tv, na.rm = TRUE)
[1] 12
R> range(d$heures.tv, na.rm = TRUE)
[1] 0 12
On peut lui ajouter la fonction median, qui donne la valeur médiane, et la très utile summary qui donne toutes ces informations ou presque en une seule fois, avec en plus les valeurs des premier et troisième quartiles et le nombre de valeurs manquantes (NA) :
2.
3.
4.
5.
R> median(d$heures.tv, na.rm = TRUE)
[1] 2
R> summary(d$heures.tv)
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.000 1.000 2.000 2.247 3.000 12.000 5.000
Histogramme
Tout cela est bien pratique, mais pour pouvoir observer la distribution des valeurs d'une variable quantitative, il n'y a quand même rien de mieux qu'un bon graphique.
On peut commencer par un histogramme de la répartition des valeurs. Celui-ci peut être généré très facilement avec la fonction hist, comme indiqué figure 3.1 ci-dessous.
Ici, les options main, xlab et ylab permettent de personnaliser le titre du graphique, ainsi que les étiquettes des axes. De nombreuses autres options existent pour personnaliser l'histogramme, parmi celles-ci on notera :
R> hist(d$heures.tv, main = "Nombre d'heures passées devant la télé par jour",
+ xlab = "Heures", ylab = "Effectif")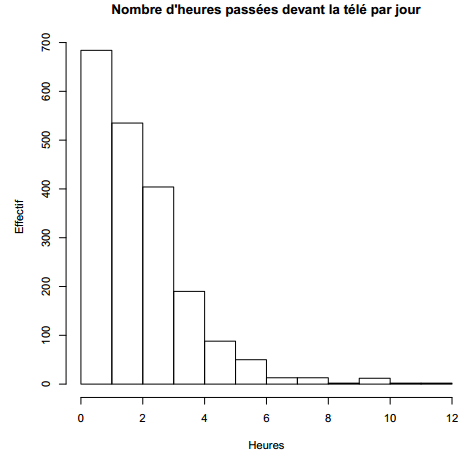
R> hist(d$heures.tv, main = "Heures de télé en 7 classes",
+ breaks = 7, xlab = "Heures", ylab = "Proportion", probability = TRUE,
+ col = "orange")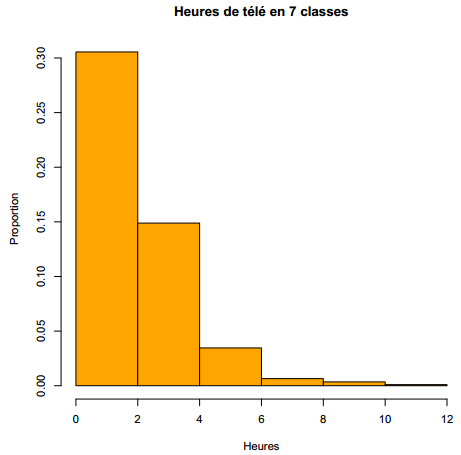
- probability si elle vaut
TRUE, l'histogramme indique la proportion des classes de valeurs au lieu des effectifs. - breaks permet de contrôler les classes de valeurs. On peut lui passer un chiffre, qui indiquera alors le nombre de classes, un vecteur, qui indique alors les limites des différentes classes, ou encore une chaîne de caractères ou une fonction indiquant comment les classes doivent être calculées.
- col la couleur de l'histogramme(11).
Deux exemples sont donnés figure 3.2 et figure 3.3, ci-dessous.
Voir la page d'aide de la fonction hist pour plus de détails sur les différentes options.
R> hist(d$heures.tv, main = "Heures de télé avec classes spécifiées",
+ breaks = c(0, 1, 4, 9, 12), xlab = "Heures", ylab = "Proportion",
+ col = "red")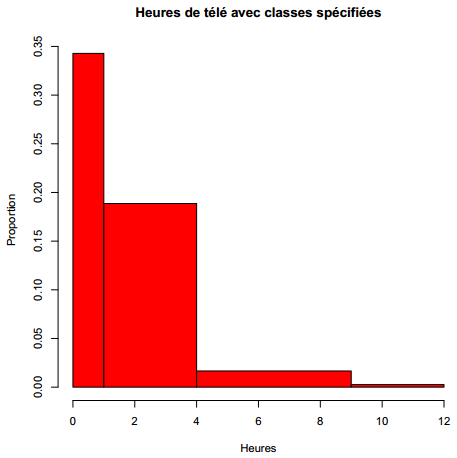
R> boxplot(d$heures.tv, main = "Nombre d'heures passées devant la télé par\njour",
+ ylab = "Heures")Boîtes à moustaches
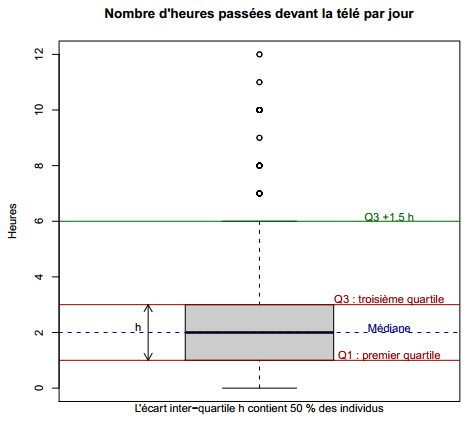
Les boîtes à moustaches, ou boxplot en anglais, sont une autre représentation graphique de la répartition des valeurs d'une variable quantitative. Elles sont particulièrement utiles pour comparer les distributions de plusieurs variables ou d'une même variable entre différents groupes, mais peuvent aussi être utilisées pour représenter la dispersion d'une unique variable. La fonction qui produit ces graphiques est la fonction boxplot. On trouvera un exemple figure 3.4.
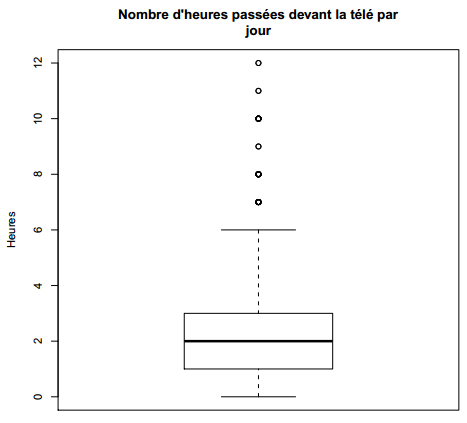
Comment interpréter ce graphique ? On le comprendra mieux à partir de la figure 3.5 ci-dessous(12).
Le carré au centre du graphique est délimité par les premier et troisième quartiles, avec la médiane représentée par une ligne plus sombre au milieu. Les « fourchettes » s'étendant de part et d'autre vont soit jusqu'à la valeur minimale ou maximale, soit jusqu'à une valeur approximativement égale au quartile.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
R> boxplot(d$heures.tv, col = grey(0.8), main = "Nombre d'heures passées devant la télé par jour", ylab = "Heures")
R> abline(h = median(d$heures.tv, na.rm = TRUE), col = "navy", lty = 2)
R> text(1.35, median(d$heures.tv, na.rm = TRUE) + 0.15, "Médiane", col = "navy")
R> Q1 <- quantile(d$heures.tv, probs = 0.25, na.rm = TRUE)
R> abline(h = Q1, col = "darkred")
R> text(1.35, Q1 + 0.15, "Q1 : premier quartile", col = "darkred", lty = 2)
R> Q3 <- quantile(d$heures.tv, probs = 0.75, na.rm = TRUE)
R> abline(h = Q3, col = "darkred")
R> text(1.35, Q3 + 0.15, "Q3 : troisième quartile", col = "darkred", lty = 2)
R> arrows(x0 = 0.7, y0 = quantile(d$heures.tv, probs = 0.75,
+ na.rm = TRUE), x1 = 0.7, y1 = quantile(d$heures.tv, probs = 0.25,
+ na.rm = TRUE), length = 0.1, code = 3)
R> text(0.7, Q1 + (Q3 - Q1)/2 + 0.15, "h", pos = 2)
R> mtext("L'écart interquartile h contient 50 % des individus", side = 1)
R> abline(h = Q1 - 1.5 * (Q3 - Q1), col = "darkgreen")
R> text(1.35, Q1 - 1.5 * (Q3 - Q1) + 0.15, "Q1 -1.5 h", col = "darkgreen", lty = 2)
R> abline(h = Q3 + 1.5 * (Q3 - Q1), col = "darkgreen")
R> text(1.35, Q3 + 1.5 * (Q3 - Q1) + 0.15, "Q3 +1.5 h", col = "darkgreen", lty = 2)
R> boxplot(d$heures.tv, main = "Nombre d'heures passées devant la télé par\njour", ylab = "Heures")
R> rug(d$heures.tv, side = 2)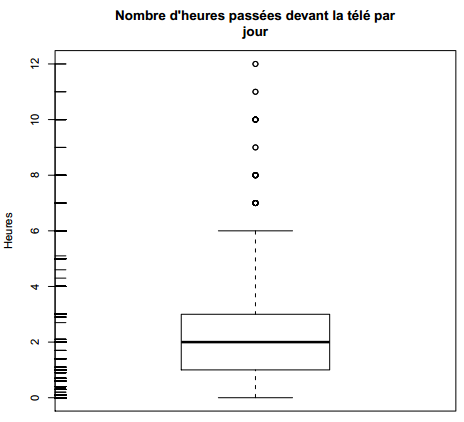
Le plus proche est plus 1,5 fois l'écart interquartile. Les points se situant en dehors de cette fourchette sont représentés par des petits ronds et sont généralement considérés comme des valeurs extrêmes, potentiellement aberrantes.
On peut ajouter la représentation des valeurs sur le graphique pour en faciliter la lecture avec des petits traits dessinés sur l'axe vertical (fonction rug), comme sur la figure 3.6.
Variable qualitative▲
Tris à plat
La fonction la plus utilisée pour le traitement et l'analyse des variables qualitatives (variable prenant ses valeurs dans un ensemble de modalités) est sans aucun doute la fonction table, qui donne les effectifs de chaque modalité de la variable.
R> table(d$sexe)
Homme Femme
899 1101Le tableau précédent nous indique que parmi nos enquêtés, on trouve 894 hommes et 1106 femmes.
Quand le nombre de modalités est élevé, on peut ordonner le tri à plat selon les effectifs à l'aide de la fonction sort.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
20.
21.
sR> table(d$occup)
Exerce une profession Chomeur Etudiant, eleve
1049 134 94
Retraite Retire des affaires Au foyer
392 77 171
Autre inactif
83
R> sort(table(d$occup))
Retire des affaires Autre inactif Etudiant, eleve
77 83 94
Chomeur Au foyer Retraite
134 171 392
Exerce une profession
1049
R> sort(table(d$occup), decreasing = TRUE)
Exerce une profession Retraite Au foyer
1049 392 171
Chomeur Etudiant, eleve Autre inactif
134 94 83
Retire des affaires
77
À noter que la fonction table exclut par défaut les non-réponses du tableau résultat. L'utilisation de summary permet l'affichage du tri à plat et du nombre de non-réponses :
R> summary(d$trav.satisf)
Satisfaction Insatisfaction Equilibre NA's
480 117 451 952Pour obtenir un tableau avec la répartition en pourcentages, on peut utiliser la fonction freq de l'extension rgrs.
2.
3.
4.
5.
6.
7.
8.
9.
10.
R> freq(d$qualif)
n %
Ouvrier specialise 203 10.2
Ouvrier qualifie 292 14.6
Technicien 86 4.3
Profession intermediaire 160 8.0
Cadre 260 13.0
Employe 594 29.7
Autre 58 2.9
NA 347 17.3
La colonne n donne les effectifs bruts et la colonne % la répartition en pourcentages. La fonction accepte plusieurs paramètres permettant d'afficher les totaux, les pourcentages cumulés, de trier selon les effectifs ou de contrôler l'affichage. Par exemple :
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
R> freq(d$qualif, cum = TRUE, total = TRUE, sort = "inc", digits = 2,
+ exclude = NA)
n % %cum
Autre 58 3.51 3.51
Technicien 86 5.20 8.71
Profession intermediaire 160 9.68 18.39
Ouvrier specialise 203 12.28 30.67
Cadre 260 15.73 46.40
Ouvrier qualifie 292 17.66 64.07
Employe 594 35.93 100.00
Total 1653 100.00 100.00
La colonne %cum indique ici le pourcentage cumulé, ce qui est, dans ce cas, une très mauvaise idée puisque pour ce type de variable cela n'a aucun sens. Les lignes du tableau résultat ont été triées par effectifs croissants, les totaux ont été ajoutés, les non-réponses exclues, et les pourcentages arrondis à deux décimales.
Pour plus d'informations sur la commande freq, consultez sa page d'aide en ligne avec ?freq ou help("freq").
Représentation graphique
Pour représenter la répartition des effectifs parmi les modalités d'une variable qualitative, on a souvent tendance à utiliser des diagrammes en secteurs (camemberts). Ceci est possible sous R avec la fonction pie, mais la page d'aide de ladite fonction nous le déconseille assez vivement : les diagrammes en secteur sont en effet une mauvaise manière de présenter ce type d'information, car l'œil humain préfère comparer des longueurs plutôt que des surfaces(13).
On privilégiera donc d'autres formes de représentations, à savoir les diagrammes en bâtons et les diagrammes de Cleveland.
Les diagrammes en bâtons sont utilisés automatiquement par R lorsque l'on applique la fonction générique plot à un tri à plat obtenu avec table. On privilégiera cependant ce type de représentations pour les variables de type numérique comportant un nombre fini de valeurs. Le nombre de frères, sœurs, demi-frères et demi-sœurs est un bon exemple, indiqué figure 3.7 ci-dessous.
Pour les autres types de variables qualitatives, on privilégiera les diagrammes de Cleveland, obtenus avec la fonction dotchart. On doit appliquer cette fonction au tri à plat de la variable, obtenu avec la fonction table. Le résultat se trouve figure 3.8.
Quand la variable comprend un grand nombre de modalités, il est préférable d'ordonner le tri à plat obtenu à l'aide de la fonction sort (voir figure 3.9).
Exercices▲
? Solution
Créer un script qui effectue les actions suivantes et exécutez-le :
- charger l'extension rgrs ;
- charger le jeu de données hdv2003.
R> plot(table(d$freres.soeurs), main = "Nombre de frères, soeurs, demi-frères et demi-soeurs", ylab = "Effectif")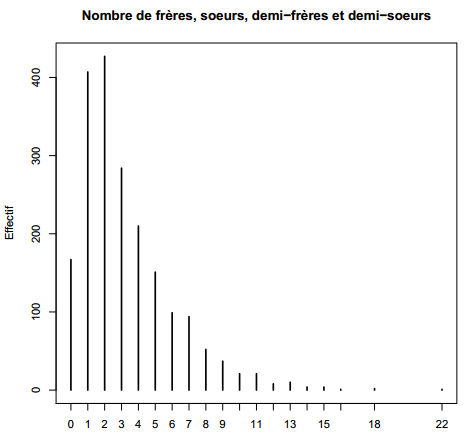
R> dotchart(table(d$clso), main = "Sentiment d'appartenance à une classe sociale", pch = 19)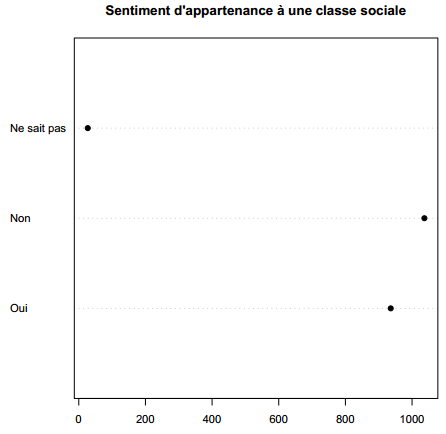
R> dotchart(sort(table(d$qualif)), main = "Niveau de qualification")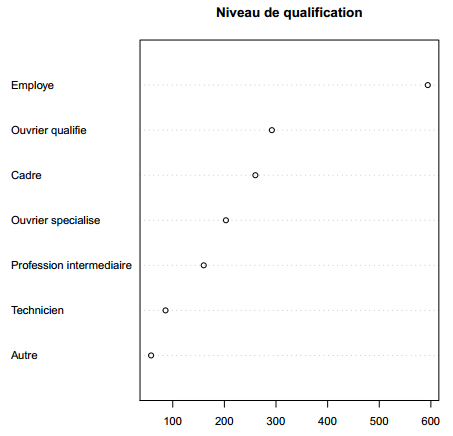
- placer le jeu de données dans un objet nommé df.
- afficher la liste des variables de df et leur type.
? Solution
Des erreurs se sont produites lors de la saisie des données de l'enquête. En fait le premier individu du jeu de données n'a pas 42 ans, mais seulement 24, et le second individu n'est pas un homme, mais une femme. Corrigez les erreurs et stockez les données corrigées dans un objet nommé df.ok.
Affichez ensuite les quatre premières lignes de df.ok pour vérifier que les modifications ont bien été prises en compte.
? Solution
Nous souhaitons étudier la répartition des âges des enquêtés (variable age). Pour cela, affichez les principaux indicateurs de cette variable. Représentez ensuite sa distribution par un histogramme en 10 classes, puis sous forme de boîte à moustache, et enfin sous la forme d'un diagramme en bâtons représentant les effectifs de chaque âge.
? Solution
On s'intéresse maintenant à l'importance accordée par les enquêtés à leur travail (variable trav.imp). Faites un tri à plat des effectifs des modalités de cette variable avec la commande table. Y a-t-il des valeurs manquantes ?
Faites un tri à plat affichant à la fois les effectifs et les pourcentages de chaque modalité.
Représentez graphiquement les effectifs des modalités à l'aide d'un diagramme de Cleveland.