


VI. CHAPITRE 6 Analyses factorielles▲
Objectifs
Ce chapitre présente deux exemples d'analyses multivariées sous R : une analyse en composantes principales (ACP) et une analyse factorielle des correspondances (AFC). À l'aide de ces méthodes, il s'agit de comprendre comment l'espace de la petite couronne parisienne s'organise, de pointer les ressemblances et différenciations entre communes au regard d'une série d'indicateurs sociodémographiques.
Prérequis
Notions théoriques sur l'analyse en composantes principales et l'analyse factorielle des correspondances.
Description des packages utilisés
Plusieurs packages proposent des fonctions pour faire des analyses factorielles, les deux principaux étant ade4 et FactoMineR qui intègrent un ensemble de méthodes d'analyse des données dite « à la française ». C'est ade4 qui sera utilisé ici, à la fois parce que le package est très bien conçu, mais aussi parce qu'il est très bien documenté. Il dispose en particulier d'un site web dédié(17) qui contribue à la qualité de cette documentation.
VI-A. Analyse en composantes principales▲
Les données utilisées sont les mêmes que dans les chapitres précédents, elles sont décrites à la Section 1.6L'exemple et les données. C'est le tableau socEco9907 qui est utilisé ici, tableau qui comporte un ensemble de variables sociodémographiques décrivant les communes de Paris et la petite couronne.
L'analyse en composantes principales est une méthode qui s'applique uniquement sur des variables quantitatives, ici sur les caractéristiques sociodémographiques des communes de la petite couronne et des arrondissements parisiens pour l'année 2007. Toutes les variables allant de la population de moins de 20 ans (P20ANS) au revenu médian (RFUCQ207) sont utilisées, ainsi que la variable de distance au centre de l'agglomération (DISTCONT) créée dans la Section 4.1Calculs simples et recodages.
VI-A-1. Réaliser l'analyse▲
L'ACP (PCA en anglais, principal components analysis) révèle la structure de différenciation entre les communes au regard des combinaisons de variables sociodémographiques contenues dans le tableau. Elle permet de dégager quelques axes de différentiation de nombreuses variables probablement très corrélées les unes avec les autres : les communes avec une forte proportion de cadres auront certainement un fort revenu médian et une faible proportion d'ouvriers par exemple.
Les données à analyser étant très hétérogènes quant à l'ordre de grandeur et à la dispersion, il faut d'abord centrer-réduire les variables. Cette opération consiste à centrer toutes les variables sur la même moyenne (moyenne égale à 0) et de les réduire à la même dispersion (écart-type égal à 1). Elle peut être faite en amont avec la fonction scale() ou directement dans la fonction dudi.pca() qui calcule l'ACP. C'est cette seconde option qui est adoptée ici avec les arguments center et scale.
La fonction dudi.pca() ne prenant comme argument que des variables quantitatives, les codes des communes sont ajoutés en tant que nom de lignes : ils seront ainsi conservés sans affecter l'ACP.
2.
3.
4.
5.
6.
7.
library(ade4)
row.names(socEco9907) <- socEco9907$CODGEO
pca07 <- dudi.pca(socEco9907[ , 23: 35],
center = TRUE,
scale = TRUE,
scannf = FALSE,
nf = 2)
L'objet produit par la fonction dudi.pca() contient tous les éléments nécessaires à une telle analyse, en particulier les coordonnées des variables et des individus sur les axes. On y accède comme d'habitude avec l'opérateur $ (cf. Encadré, pensez à utiliser la touche Tab pour l'autocomplétion).
VI-A-2. Examiner et interpréter les résultats▲
L'ACP consiste au passage d'un système d'observations dans un espace à p variables à un espace à p composantes principales. L'intérêt de cette méthode est de réduire les dimensions et de supprimer la colinéarité entre variables. Les composantes correspondent à des combinaisons linéaires de l'ensemble des indicateurs analysés. Elles se hiérarchisent en fonction de la variance des coordonnées des individus dans l'espace euclidien des variables. Les composantes principales sont des variables synthétiques qui permettent d'identifier le(s) facteur(s) principal(-aux) de différenciation au sein de la matrice initiale.
Une telle analyse produit un certain nombre d'éléments pour caractériser ces composantes, à commencer par les valeurs propres (eigenvalues en anglais). Celles-ci rendent compte de l'inertie du nuage de points expliquée par chaque facteur. La somme de ces valeurs propres donne la variance totale. Pour se faire une idée de la structuration des variables, il faut examiner les parts relatives de la variance pour chaque composante ainsi que leurs parts cumulées. Ces indications sont contenues dans l'objet créé par la fonction dudi.pca(), elles sont regroupées ici dans un tableau et représentées sous forme graphique.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. |
|
|
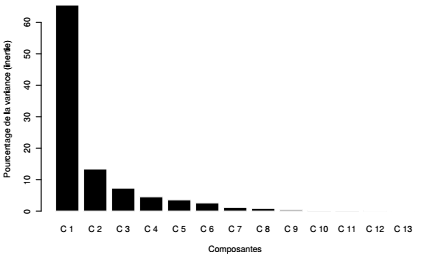
Dans cet exemple, le graphique montre que l'ensemble des variables est très structuré avec des corrélations fortes. Il apparaît que 65,5 % de l'information contenue dans le tableau initial est résumée par le premier facteur. Le pouvoir discriminant des axes suivants est relativement faible.
L'interprétation du rôle des variables dans la structuration de l'information apportée par l'ACP s'effectue grâce à l'observation de leurs coordonnées sur les deux premiers axes : celles-ci représentent le coefficient de corrélation entre une variable et un axe.
axisCoord <- pca07$coLes coordonnées varient entre -1 et +1 : les valeurs proches de 0 correspondent à une absence de relation linéaire entre la variable et l'axe ; les valeurs absolues élevées, proches de 1, indiquent une forte corrélation entre la variable et l'axe; le signe indique si la relation est positive ou négative.
Ici, l'axe 1 indique une opposition entre les communes aisées et les communes défavorisées, il affiche des valeurs fortement négatives pour les variables suivantes : la part des non-diplômés, des chômeurs, des intérimaires, des employés et des ouvriers. Il affiche au contraire des valeurs proches de 1 pour la part des cadres et le revenu médian. L'axe 2 de l'analyse rend compte, quant à lui, d'une opposition entre communes ayant une forte proportion de professions intermédiaires au sein de la population d'actifs occupés (PINT07) et les autres.
La visualisation du premier plan factoriel (repère du plan défini par les deux premiers axes) permet de mieux comprendre comment les deux premiers facteurs structurent l'espace des variables. La fonction s.corcircle() permet de l'afficher. On y ajoute également la variable de distance au centre de l'agglomération pour voir comment elle se situe vis-à-vis des autres. Cette variable de distance est une variable dite « supplémentaire », elle est simplement projetée sur le plan, mais n'entre pas en ligne de compte dans le calcul des composantes. C'est la fonction supcol() qui permet d'afficher cette variable, elle doit être centrée-réduite en cohérence avec les options définies plus haut pour l'analyse.
|
Sélectionnez 1. 2. 3. 4. 5. |
|
|
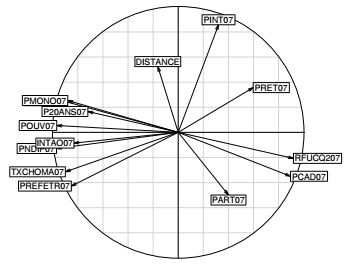
On remarque notamment que les communes ayant une part élevée de professions intermédiaires au sein des individus actifs sont plutôt corrélées avec une distance à Paris importante.
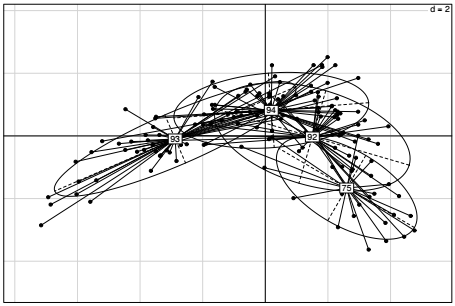
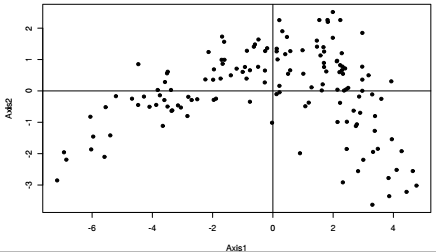
Une fois analysées les relations entre variables, il s'agit de s'intéresser à la façon dont les individus statistiques, ici les communes, se positionnent sur les plans factoriels. Il est souvent intéressant de surimposer à la position des individus statistiques une variable de regroupement représentée par une ellipse, ici le département d'appartenance des communes. Le centre de l'ellipse est le centre de gravité du sous-groupe et les points sont reliés au barycentre correspondant à leur sous-groupe. Il est également possible d'utiliser la fonction générique plot(), ou d'autres fonctions graphiques (cf. Chapitre 9CHAPITRE 9 Focus sur la visualisation graphique), en récupérant les coordonnées des individus.
|
Sélectionnez |
|
|
|
Sélectionnez |
|
|
VI-A-3. Analyse des contributions▲
Une fois calculées les composantes principales, il est important de faire une analyse des contributions. Deux types de contributions peuvent être analysées : la contribution des variables à la formation des axes ainsi que la contribution des individus statistiques. Ce type d'analyse est absolument nécessaire dans le cas d'une ACP assortie d'une pondération, elle reste importante même sur un tableau non pondéré comme c'est le cas ici.
La contribution d'une variable rend compte du rôle qu'elle a joué dans la formation de l'axe. L'ensemble de ces contributions pour un axe équivaut à 1, puisque les contributions s'obtiennent en effectuant le rapport entre le carré de la coordonnée de la variable sur l'axe et la valeur propre de ce dernier (i.e. la somme des carrés des coordonnées de l'ensemble des variables sur l'axe).
Ces contributions pourraient être calculées par l'utilisateur, mais le package ade4 fournit une fonction qui fait le travail : la fonction inertia.dudi(). Les arguments row.inertia et col.inertia indiquent que les contributions des individus et des variables doivent être renvoyées.
2.
3.
4.
5.
contribPca <- inertia.dudi(pca07,
row.inertia = TRUE,
col.inertia = TRUE)
contribVar <- contribPca$col.abs
Les hauteurs des contributions des différentes variables (notez que ces contributions sont exprimées en 1/10 000) montrent que le premier facteur résulte d'une combinaison de variables plutôt que d'une spécialisation dans un domaine particulier, la dispersion autour des valeurs centrales étant relativement faible. Ceci montre également que la plupart de ces variables sont corrélées les unes avec les autres, à l'exception des professions intermédiaires et des artisans commerçants.
La contribution d'un individu à la formation d'un axe permet donc de déterminer la part qu'un individu prend dans la variance d'un axe (ici le premier axe factoriel). On peut ainsi regarder quelles sont les communes qui ont le plus contribué à la formation du premier axe à l'aide de la fonction which(). La première ligne donne le code Insee des communes, et la seconde restitue leurs numéros de ligne dans le tableau de données initial. Attention, la fonction which() classe les individus selon l'ordre des lignes et non des valeurs des contributions.
2.
3.
4.
5.
6.
7.
contribIndiv <- contribPca$row.abs
contribIndivAxis1 <- as.vector(contribIndiv[ , 1])
names(contribIndivAxis1) <- row.names(contribIndiv)
head(sort(contribIndivAxis1, decreasing = TRUE))
## 93014 93079 93027 93072 93066 93008
## 421 395 386 301 299 292
On note que les communes ayant le plus contribué à la formation de l'axe 1, axe distinguant globalement les communes défavorisées (chômage, revenu médian faible, etc.) et les favorisées (cadres, revenu médian élevé), sont les communes les plus paupérisées du département de Seine Saint-Denis, en premier lieu Clichy-sous-Bois et Villetaneuse.
VI-A-4. Analyse des qualités de représentation▲
La qualité de la représentation d'une variable par un axe été calculée dans la section précédente par la fonction inertia.dudi(). Elle renseigne sur la part de la variable qu'explique l'axe associé et correspond au carré de sa coordonnée sur l'axe, donc du coefficient de corrélation. La somme des carrés des coordonnées d'une variable sur l'ensemble des axes est égale à 1. La fonction utilisée l'exprime en 1/10 000 et conserve le signe de la contribution.
qualVar <- contribPca$col.relPour faciliter l'analyse des qualités de représentation des variables, une représentation graphique peut être utile : il s'agit d'un diagramme en bâtons horizontal pour représenter les variables sur l'axe 1, seules les valeurs absolues sont conservées et celles-ci sont divisées par 10 000 pour les situer entre 0 et 1.
|
Sélectionnez 1. 2. 3. 4. 5. 6. |
|
|
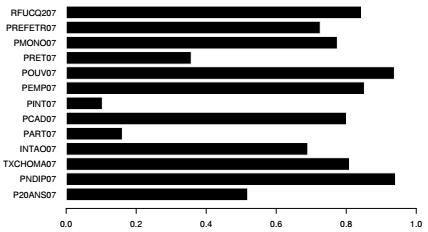
On remarque que les variables RFUCQ207, POUV07, PEMP07, TXCHOMA07, PNDIP07 sont particulièrement bien représentées par le premier facteur, puisque ce dernier rend compte de plus de 80 % de la dispersion autour de ces six variables.
La qualité de la représentation d'un individu sur les axes factoriels est elle aussi calculée par la fonction inerti.dudi(). Elle mesure la proximité d'un individu à un axe. L'analyse sur le premier axe factoriel rend particulièrement bien compte de la particularité de certaines communes du département de la Seine-Saint-Denis (93) et du département du Val de Marne (94).
VI-B. Analyse factorielle des correspondances▲
L'Analyse Factorielle des Correspondances (AFC, correspondence analysis en anglais) est une analyse en composantes multiples (ACP) appliquée à un tableau de contingence. Elle est appliquée ici pour mesurer les proximités statistiques entre les communes de la petite couronne parisienne et les arrondissements de la capitale au regard de l'évolution de leurs populations entre 1936 et 2008. La manipulation des fonctions et la façon d'interpréter les sorties sont très semblables dans le cas de l'AFC que dans le cas de l'ACP. C'est pourquoi l'analyse présentée dans cette section est moins détaillée que la précédente.
L'analyse porte sur les données contenues dans le tableau popCom3608. Celui-ci dénombre les individus (ici la population résidente) correspondant au croisement entre deux modalités de variables qualitatives : l'une définie en lignes (ici la commune) et l'autre en colonnes (ici les années d'observation, considérées comme les modalités d'une même variable de population).
VI-B-1. Réaliser l'analyse▲
En explorant les variables de population à toutes les dates avec les outils présentés dans les chapitres précédents, on remarque que la population moyenne des communes de l'agglomération parisienne n'a pas augmenté de façon linéaire entre 1936 et 2008. Trois phases peuvent être définies : une phase de croissance allant de 1936 à 1968, puis une phase de décroissance entre 1968 et 1982, et enfin une nouvelle phase de croissance entre 1982 et 2008. En outre, alors que la population la plus faible observée a eu tendance à augmenter au cours du temps, passant de 276 habitants en 1936 à 1680 habitants en 2008, le nombre d'habitants de la commune la plus peuplée a décru, passant de 258 599 habitants en 1936 à 234 091 habitants en 2008.
La construction d'une AFC va permettre de caractériser plus en détail les dynamiques démographiques des communes. En effet, en tant que méthode d'analyse de données multivariées, l'AFC donne lieu à une hiérarchisation de l'information contenue dans le tableau de contingence initial. Elle permet de mesurer les proximités statistiques entre modalités d'une variable et individus, ainsi que de comparer les profils-lignes et profils-colonnes entre eux. Il faut noter que les résultats de l'AFC ne sont pas dépendants de l'analyse de l'un ou de l'autre, les transformations opérées sur les individus et les variables du tableau étant parfaitement symétriques.
L'analyse est effectuée avec la fonction dudi.coa() du package ade4. Comme dans l'ACP, l'objet créé par la fonction contient tous les éléments nécessaires à la visualisation des résultats et à leur interprétation.
2.
3.
4.
row.names(popCom3608) <- popCom3608$CODGEO
coaPop <- dudi.coa(popCom3608[ , 3: 11],
scannf = FALSE,
nf = 2)
VI-B-2. Interpréter les résultats▲
Tout comme dans le cas d'une ACP, on observe les valeurs propres associées aux différents axes factoriels afin de déterminer lesquels d'entre eux vont être analysés. Le graphique des valeurs propres apporte une aide visuelle à l'interprétation.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. |
|
|
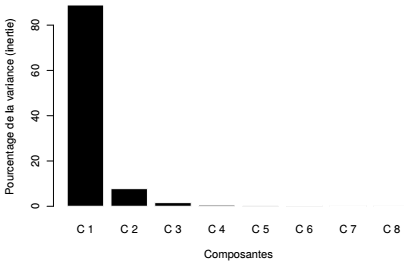
L'AFC rend compte d'une structuration particulièrement marquée des données. En effet, le premier axe factoriel explique la plus grande part de la variance totale contenue dans le tableau de contingence (88,9 %). Le second facteur résume 7,8 % de l'inertie totale du nuage de points, ainsi 96,68 % de l'information sont concentrés sur les deux premiers axes.
Pour aller plus loin dans l'analyse des résultats de l'AFC, il faut étudier plus en détail les coordonnées des individus et des variables sur les axes factoriels. Les coordonnées des individus et des variables sur les axes factoriels sont mesurées par les valeurs de leurs projections sur l'axe et rendent compte des positions relatives des individus et des variables les uns par rapport aux autres et par rapport au centre de gravité du nuage (i.e. le profil ligne moyen). La moyenne des valeurs des projections des individus sur l'axe est nulle et la variance associée à ces coordonnées équivaut à la valeur propre associée au facteur. En règle générale, le premier axe factoriel exprime une opposition entre groupes d'individus et/ou variables (coordonnées positives versus neutres versus négatives), alors que les axes suivants définissent des différenciations internes à ces groupes.
Afin de faciliter l'interprétation visuelle des projections des deux variables, il est préférable de ne pas utiliser le graphique par défaut du package ade4, mais de représenter avec la fonction générique plot() les coordonnées des communes sur les deux premiers axes (cercles gris, arguments pch et col). Les projections des années d'observation sur le plan sont également ajoutées avec la fonction points() et la fonction text() par des losanges noirs reliés les uns aux autres (arguments col, pch et type). L'argument pos précise la position du label (1-Bas ; 2- Gauche ; 3-Haut ; 4-Droite) : ici on donne à cet argument un vecteur de longueur 9 pour préciser la position de chaque label et éviter les superpositions.
|
Sélectionnez 1. 2. 3. 4. 5. 6. 7. |
|
|
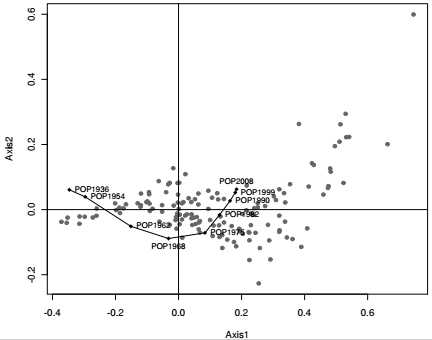
L'observation du premier plan factoriel indique que le premier axe oppose les communes ayant connu une croissance relative de leur population plus forte en début de période à celles dont cette croissance relative de la population a été plus élevée en fin de période. Le second axe factoriel oppose quant à lui, et ce assez logiquement, les communes ayant connu une croissance relative plus importante en milieu de période aux autres. Au centre du plan, on retrouve des communes affichant un profil de croissance de population relativement moyen, ou ayant connu de nombreuses bifurcations dans la croissance de leur population au cours de la période.
La position des communes sur les deux axes pourra être étudiée plus en détail par l'analyse de leurs coordonnées sur les deux facteurs, la visualisation des ellipses peut également être utile. Comme pour l'ACP, il est intéressant d'examiner les contributions, ce qui se fait, comme dans la section précédente, avec la fonction inertia.dudi().
|
Sélectionnez 1. 2. |
|
|
|
Sélectionnez 1. 2. 3. |
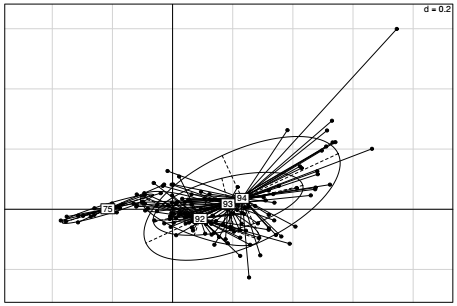
Les dynamiques de peuplement dans l'agglomération parisienne sont typiques d'un modèle monocentrique : la temporalité de l'étalement dépend très directement de la distance au centre, ou plus exactement de l'accès au centre par les réseaux de transport. Les communes qui se sont peuplées dans le début de période, des années 1930 aux années 1960 sont principalement les arrondissements parisiens. En banlieue, ce sont d'abord les communes les plus proches de Paris et les mieux desservies qui ont vu leur population augmenter, c'est-à-dire principalement les communes des Hauts-de-Seine. Finalement les communes les plus lointaines se sont peuplées sur la dernière période, en particulier dans les départements de Seine Saint-Denis et du Val-de-Marne.
Cette analyse factorielle pourrait utilement être suivie d'une procédure de classification qui viserait à dresser des profils de communes en fonction de l'évolution de leur population. Cette analyse est présentée à la Section 7.3Couplage analyse factorielle - classification.